Playing with the HTTP send/response cycle in Ruby, without Faraday ("HTTP Yeah You Know Me" project)
Article Table of Contents
- Finding GET requests/responses in the wild
- Setting up my own requests in Ruby, seeing headers in Postman
- Congrats!
- Iteration 3: supporting params
As part of the HTTP Server project.
First, I’m working through Practicing Ruby’s “Implementing an HTTP File Server” for general practice and understanding.
I’m going to use Postman to capture traffic and try to replicate some of the things the guides reference.
Lastly, I just found Jeff Casamir’s walkthrough of almost everything I’ve discovered in the last week. Save yourself the time, and go read it here
Finding GET requests/responses in the wild #
First, I need to configure postman to show request/response headers, like what the guides indicate:
# HTTP Request
GET /file.txt HTTP/1.1
User-Agent: ExampleBrowser/1.0
Host: example.com
Accept: */*
# HTTP Response
HTTP/1.1 200 OK
Content-Type: text/plain
Content-Length: 13
Connection: close
hello world
Turns out Postman cannot do this caputuring by default.
So, follow these instructions
Lets first look at some get requests in the wild:
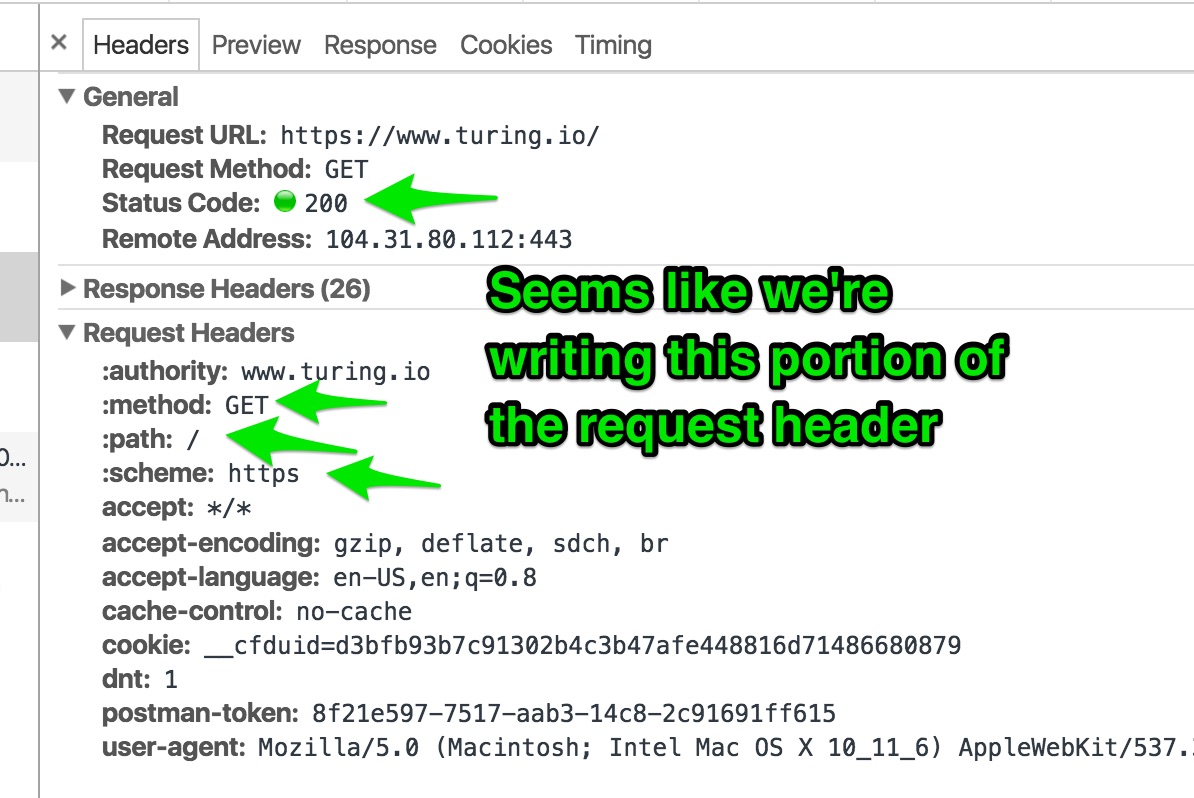
Using Postman, I made a get request for turing.io. I get back lots of HTML, etc. But I want to see the headers. The “Headers” tab in the Postman request isn’t really helpful.

So, we’ll look at “network traffic” per the following:
right click inside postman > “inspect” > Network tab > “clear” the screen, if anything is in it, > switch back to postman, re-send the GET request > switch back to “inspect window”.
Looks like this:

OK, cool. This stuff looks promising:

Everything I highlighted corresponds to items mentioned in the instructions. This is approaching “interesting”, and I feel like there might be an insight around the corner.
Setting up my own requests in Ruby, seeing headers in Postman #
So, I can find the headers for any GET request I might make in the wild, so now I’m going to try to do the same setup with my own little ruby server, per this guide.
I’m following the author’s instructions to:
To begin, let’s build the simplest thing that could possibly work: a web server that always responds “Hello World” with HTTP 200 to any request
I’m writing everything in the http_yeah_you_know_me directory. I’ll delete it before pushing a final project version to Github.
require 'socket'
server = TCPServer.new('localhost', 2345)
Turns out TCPServer is a Ruby class, just like an enumerable or array or hash or Fixnum or NilClass, etc. Cool.
It’s got some methods that I won’t worry about right now.
Moving on:
loop do
socket = server.accept
request = socket.gets
STDERR.puts request
response = "Hello World!\n"
socket.print "HTTP/1.1 200 OK\r\n" +
"Content-Type: text/plain\r\n" +
"Content-Length: #{response.bytesize}\r\n" +
"Connection: close\r\n"
The loop seems interesting. I tested the simple_server.rb file before writing this, and it seemed that the socket closed as soon as a single request was made. (I.E. I’d start the “server”, and as soon as I interacted with it in any way, it would do something and close. So I wonder if this loop will keep the server open.
Please read through the commented version of what I’m writing above. It’s a good explenation, but I’ve noticed something interesting. We’re printing a HTTP Response. See the HTTP/1.1 200OK in the first line? Does that look familiar?
socket.print "\r\n"
socket.print response
socket.close
end
That first line is, according to the comments, the required new-line to tell the server (or something) that the header is over and the body content is coming. The response references a previously defined variable of response = "Hello World!\n", so we’re printing hello world as the content.
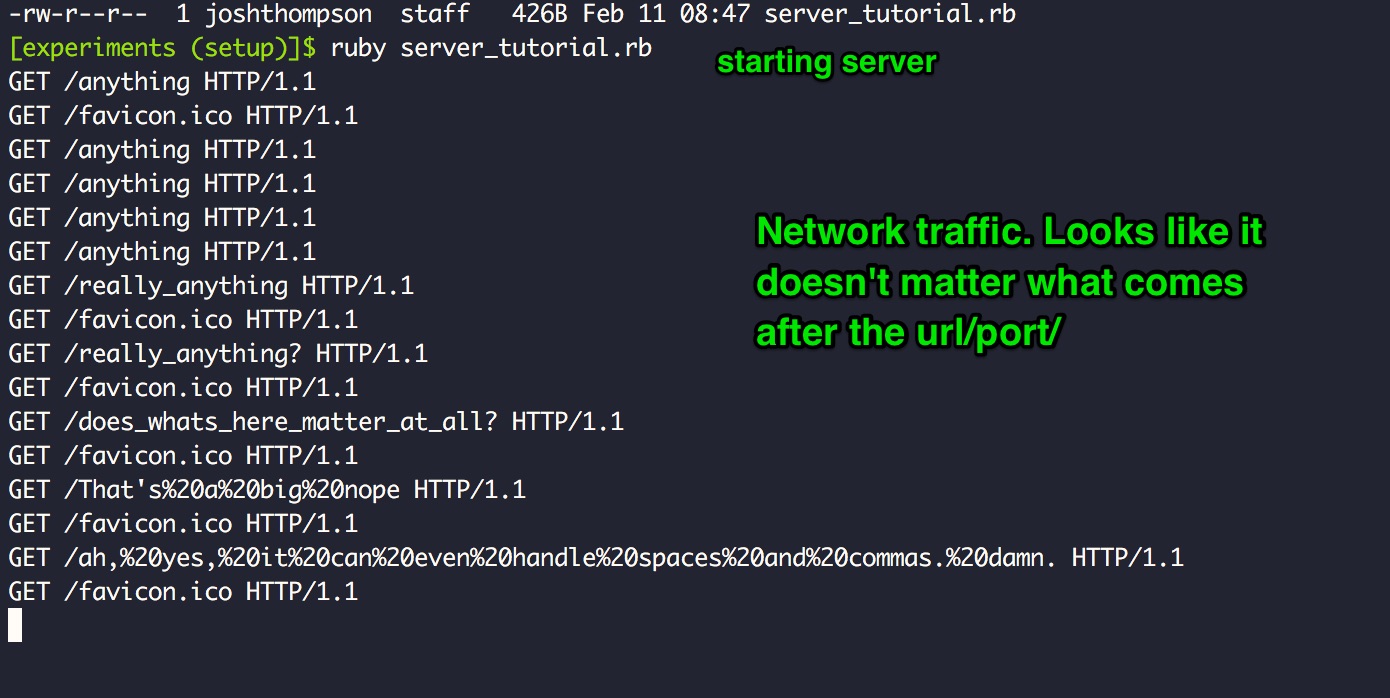
Lets try to fire this thing up. Save file, run as a program from the command line, and visit http://localhost:2345/anything.
Looks like it worked:
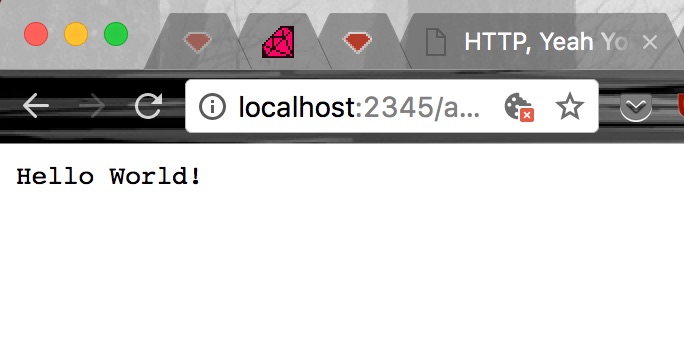
But it’s not very exciting. Lets get back into Postman and try to dig deeper:
Now we’re getting more. I can see every parameter passed through to the server, and it is staying open! (Put a flag in that. The “simple server” we made for HTTP_yeah_you_know_me can be kept open with a loop. Cool.
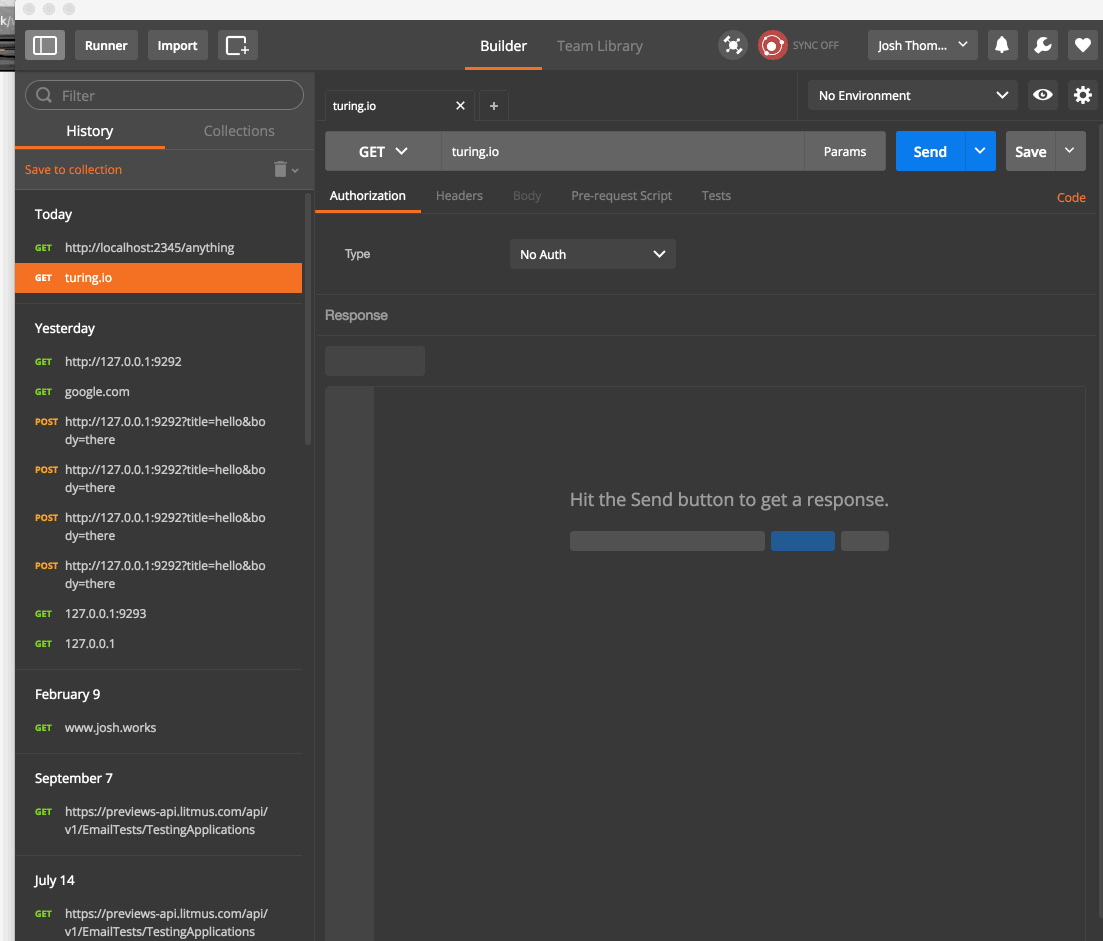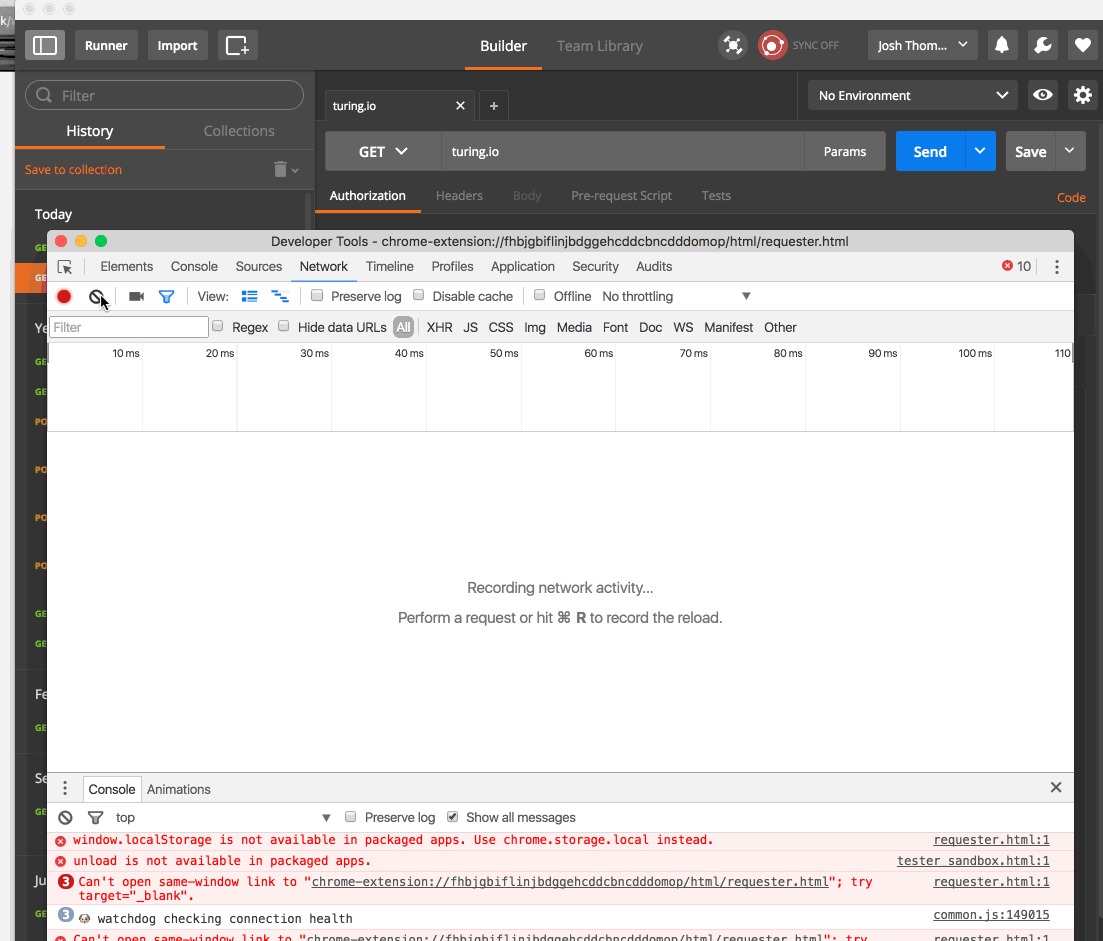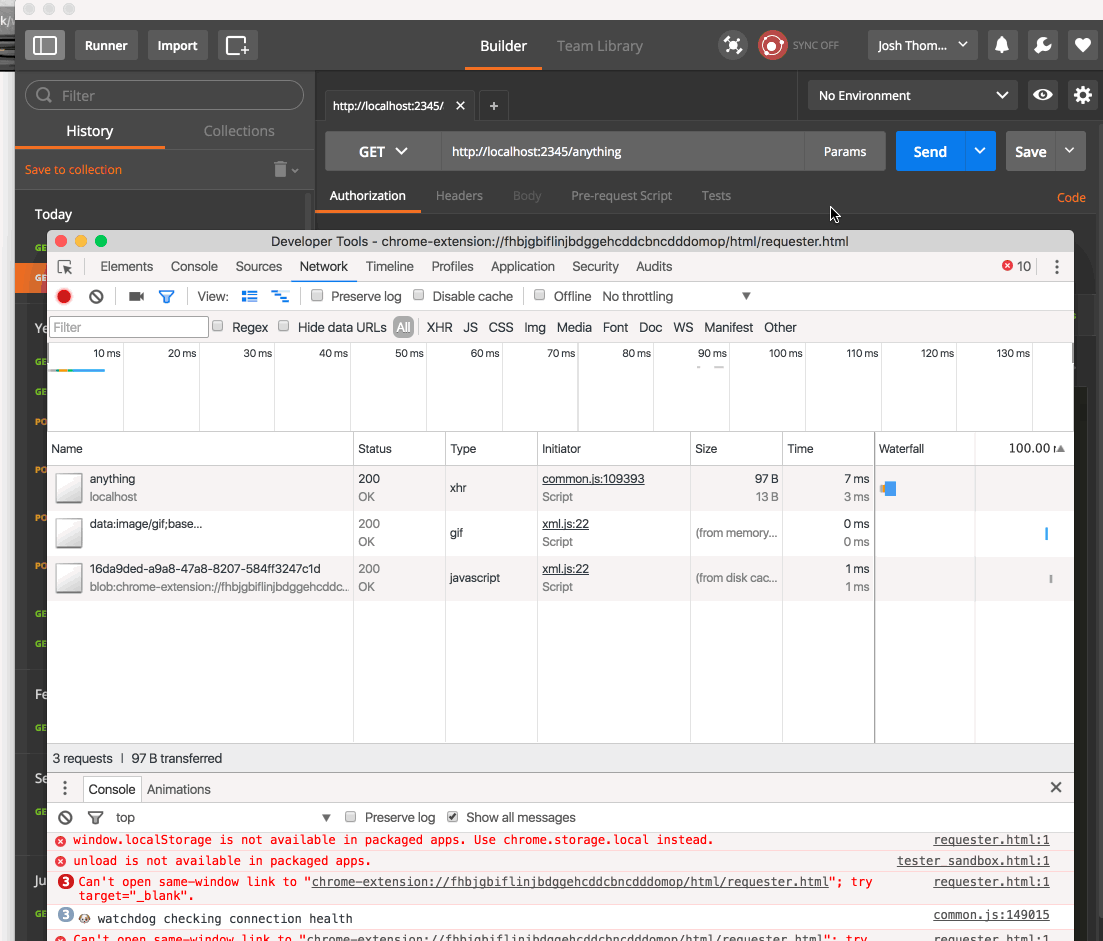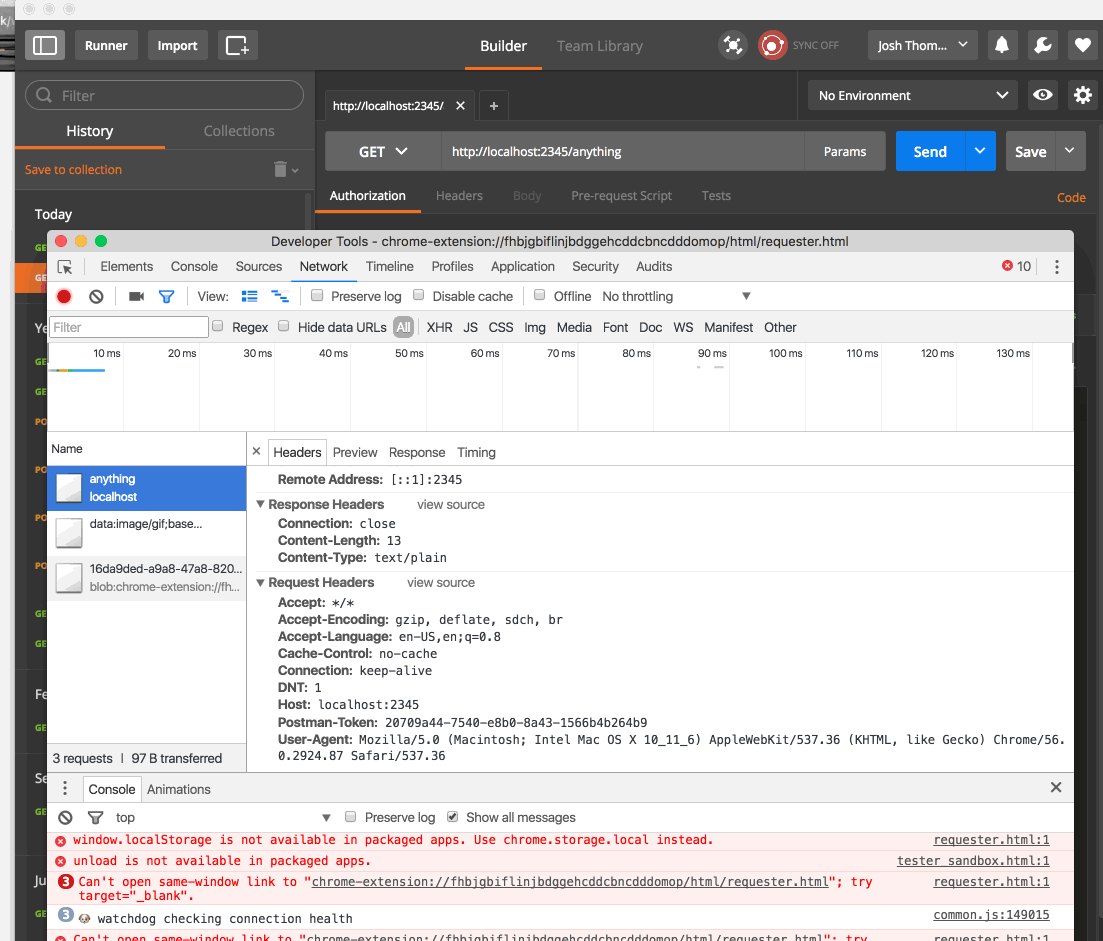
And, as the author mentioned in the tutorial, this seems to be working:
# Log the request to the console for debugging
STDERR.puts request
And, as recommended, open up another window and run curl --verbose -XGET http://localhost:2345/anything_you_want_to_put_here
I like to understand shell commands when I run them, so if you look at the MAN pages for curl, you can find what each of those flags means.
curl --verbose means “curl talks a lot”, and more importantly, lines beginning with > is header data sent by curl, and lines beginning with < is header data received by curl. Lines beginning with * is additional info added by CURL.
I suspect this will be important.
-XGET is a flag that, according to the MAN page, “specifies custom request method”. the -X lives by itself, and whatever follows is what it makes as the request method, so -XGET, -XPOST, and -XDELETE are all probably valid uses of the flag.
Here’s the output for curl --verbose -XGET htpp://localhost:23454/whatever_blah_blah_blah
[experiments (setup)]$ curl --verbose -XGET http://localhost:2345/whatever_blah_blah_blah
Note: Unnecessary use of -X or --request, GET is already inferred.
* Trying ::1...
* TCP_NODELAY set
* Connected to localhost (::1) port 2345 (#0)
> GET /whatever_blah_blah_blah HTTP/1.1
> Host: localhost:2345
> User-Agent: curl/7.52.1
> Accept: */*
>
< HTTP/1.1 200 OK
< Content-Type: text/plain
< Content-Length: 13
< Connection: close
<
Hello World!
* Curl_http_done: called premature == 0
* Closing connection 0
Cool. We’ve got data sent by curl (prepended with >), data received (prepended with <), what is actually passed through (the one line without any characters at the beginning) and of course, additional data returned by CURL. (begins with *).
Phew. Learning some stuff, eh? I still don’t know what most of this means, but it’s building out a mental model. So, keep experimenting. You’re typing all these commands yourself, right? no copy-pasta from here. That’ll keep you from learning as much.
Congrats! #
This is the end of the first section of the post, building a simple server. Now, moving along, gonna build a more complex one.
This is where I look over my notes, take a walk, and get some coffee. This is a lot of work, so let it sink in and consolidate.
Serving files over HTTP #
I’m now working through the second half of this tutorial.
He says:
For each incoming request, we’ll parse the
Request-URIheader and translate it into a path to a file within the server’s public folder.
What’s the request URI? How’s it different from a URL? I’m not sure, but I can infer some things. Mostly, looking at some of the results of poking around in different pages in Postman, and looking at the results, I think we can figure this out. (Googling around for “URI vs URL didn’t help a lot)
We know that the first line of a HTTP Request looks like this: GET / HTTP/1.1. This is three things:
- GET is the method.
- / is the “path”
- HTTP/1.1 is the protocal (or possibly called the “scheme”).
So, if I go to the root of a website (like www.turing.io) the header will be: GET / HTTP/1.1.
If I go to a specific page (or resource) I’ll go to www.turing.io/our-team. What do you think the GET request would look like then? Here’s my guess:
GET /our-team HTTP/1.1
Lets fire it up in POSTMAN and see:
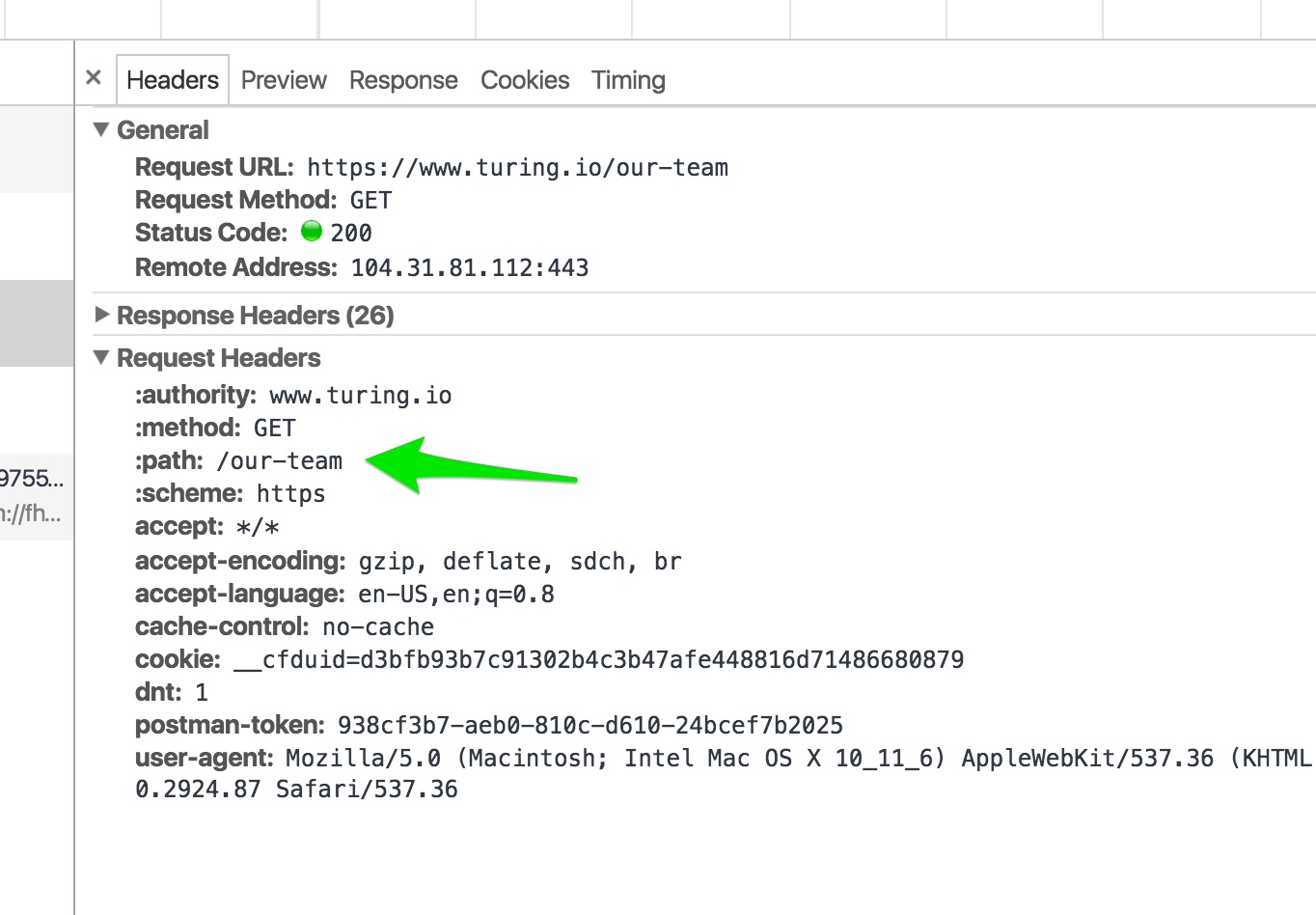
Cool. So the path is just website.com/<the_path>. Or, to tie it into ruby-speak, when we require another file, we define its from the root directory. Similar idea with the URI.
Onward.
First bit of code in the second file. (I’d start a new file from scratch, and type every line…)
require 'socket'
require 'uri'
WEB_ROOT = './public'
CONTENT_TYPE_MAPPING = {
'html' => 'text/html',
'txt' => 'text/plain',
'png' => 'image/png',
'jpg' => 'image/jpeg'
}
DEFAULT_CONTENT_TYPE = 'application/octet-stream'
Makes sense, except I have no idea what an octet-stream is. Don’t really care, though. This just is mapping input values to something that our HTTP server can understand, I believe.
def content_type(path)
ext = File.extname(path).split(".").last
CONTENT_TYPE_MAPPING.fetch(ext, DEFAULT_CONTENT_TYPE)
end
We’ve seen File.extname before, when doing FileIO stuff. So this is taking the file extension, splitting it from the file name, and trying to match it to the hash we just wrote. If it matches, it’ll pull and do something with the matching value. I.E. jpg => image/jpeg.
Onward, a bunch of other stuff that is explained in the commented out portions of the tutorial, and I barely understand it, so skipping them.
We see this again:
(You typed it out by hand, right?)
loop do
socket = server.accept
request_line = socket.gets
STDERR.puts request_line
path = requested_file(request_line)
if File.exist?(path) && !File.directory?(path)
File.open(path, "rb") do |file|
socket.print "HTTP/1.1 200 OK\r\n" +
"Content-Type: #{content_type(file)}\r\n" +
"Content-Length: #{file.size}\r\n" +
"Connection: close\r\n"
socket.print "\r\n"
IO.copy_stream(file, socket)
end
else
message = "File not found\n"
socket.print "HTTP/1.1 404 Not Found\r\n" +
"Content-Type: text/plain\r\n" +
"Content-Length: #{message.size}\r\n" +
"Connection: close\r\n"
socket.print "\r\n"
socket.print message
end
I was curious about all the \r\n characters. It’s obviously something to do with a line break.
On stack overflow, I found this:
The CRLF
\r\n, should be used according to the php documentation. Also, to conform to the RFC 2822 spec lines must be delimited by the carriage return character, CR\rimmediately followed by the line feed, LF\n.
Seems like it’s a Carriage Return Line Feed symbol, native to PHP, that inserts a really “hard” line break. That makes since, since earlier in the guide, the author mentioned that HTTP request/responses are very sensitive to line breaks and white spaces. So, I’m flagging this as “important” for later use.
And, keep following the instructions. I got it to serve up an /index.html page by default, and downloaded a few other files that I “stored” in a public directory in the same place as the server-generation script.
So, I feel like I’ve got my head a little more wrapped around server stuff in Ruby. Writing it out helps me a bit, maybe will be helpful to others, too.
Play around with building your own HTTP Response - LIVE! #
I’m keeping notes for myself and my own understanding - I’m not good at teaching that which I barely can wrap my head around, so… I apologize for the upcoming disconnectedness or holes in reasoning.
I’ve really, realy wanted to get a tool up and running that lets me talk, as a server, to something that’s expecting a given response. This is so I can get one level of abstraction lower to understand these HTTP requests/responses.
I just figured out how to do it.
We’ll use two tools, both already existing in your terminal:
- nc (Stands for “Net Cat”)
- CURL (stands for C-URL? “see URL”?)
I strongly recommend downloading and installing tldr, as it will let you more quickly explore terminal commands. We’ll be using “flags” for both the above utilities. (a flag makes a program do something other than it’s default. Like ls vs ls -l)
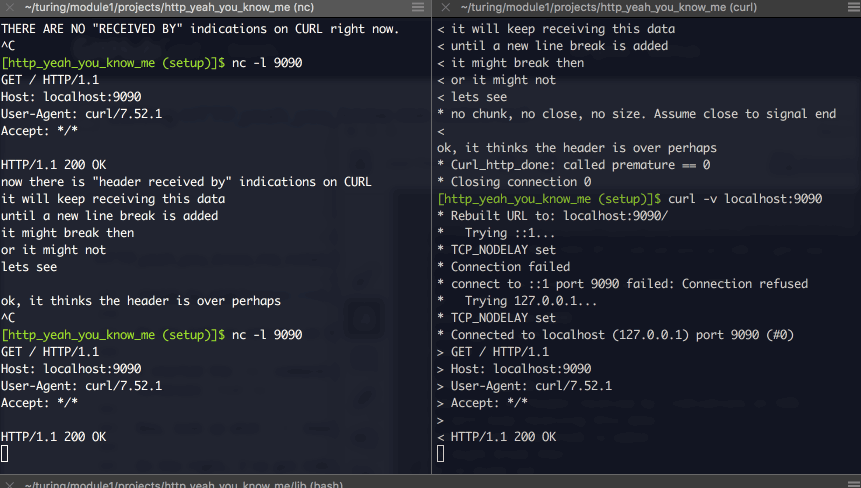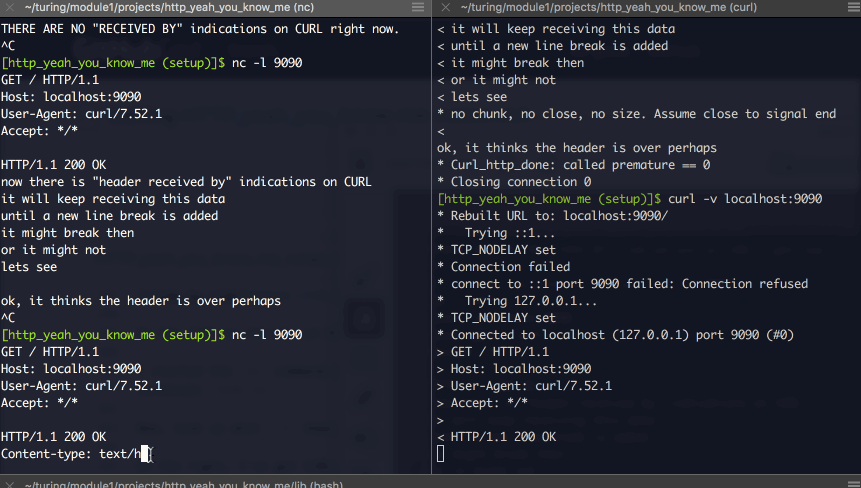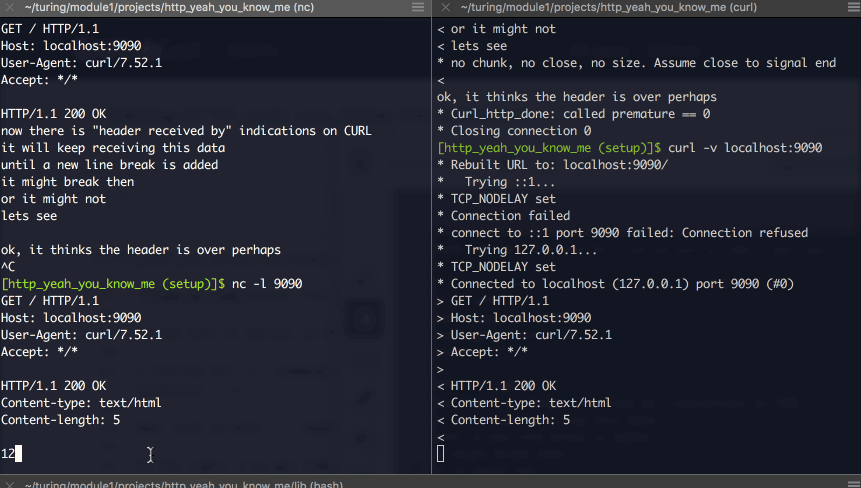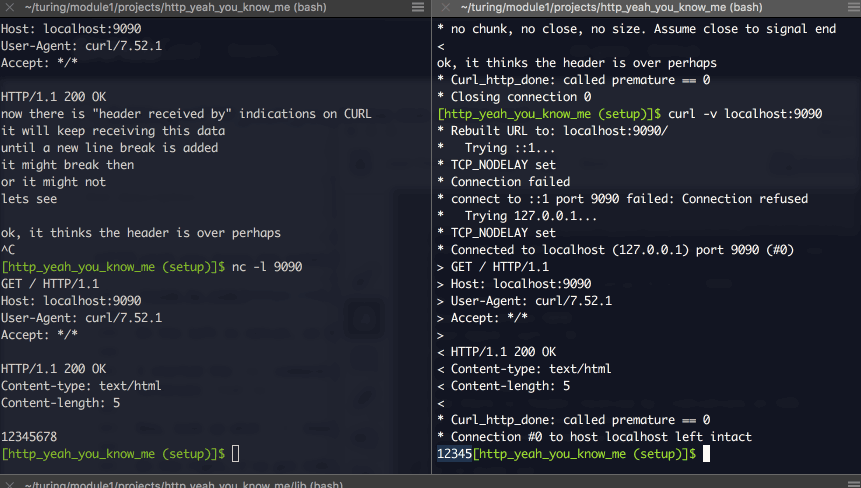
You’ll need two terminal windows side by side, like this:
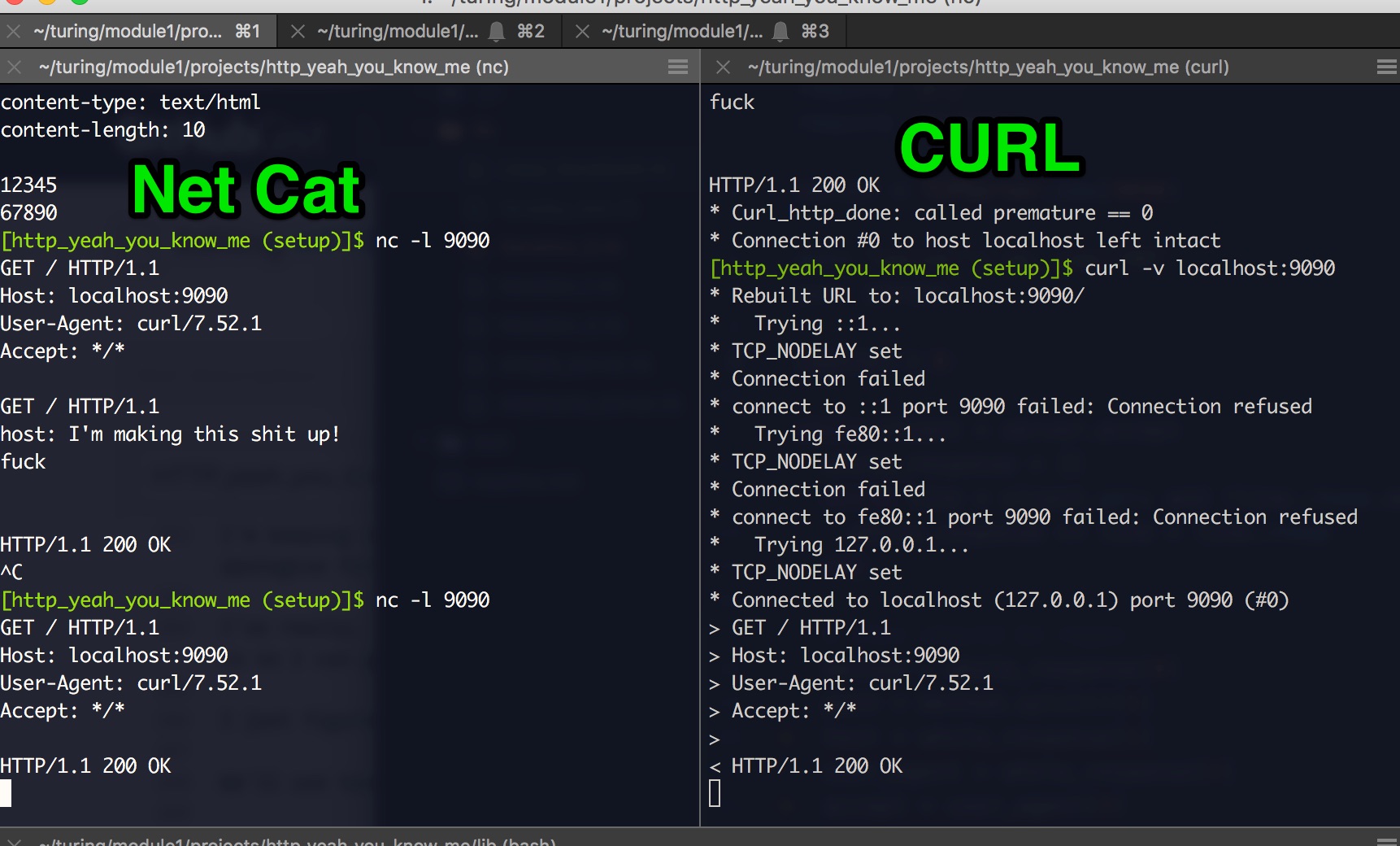
On the left is netcat, on the right is CURL.
I started the nc command on the left with nc -l 9090. If you’re reading this, please, please install the tldr tool and run (in your terminal) tldr nc.
Now, look up what -l does.
On the right, I’ve got CURL, running as curl -v localhost:9090. Look it up in TLDR, tell me what -v does. (Hint, i’ve outlines it above.)
Here’s using them in tandem:
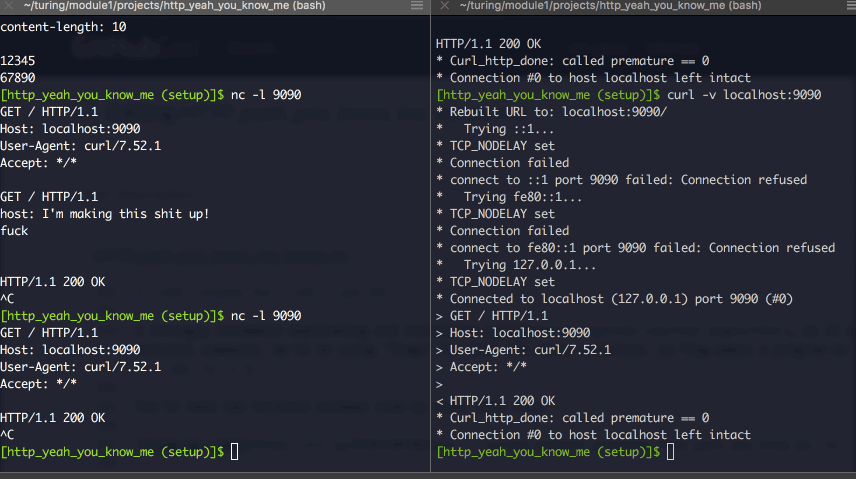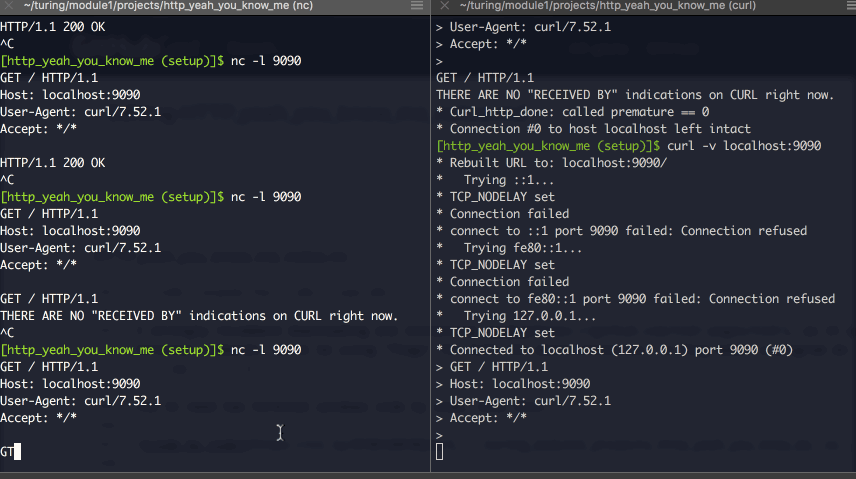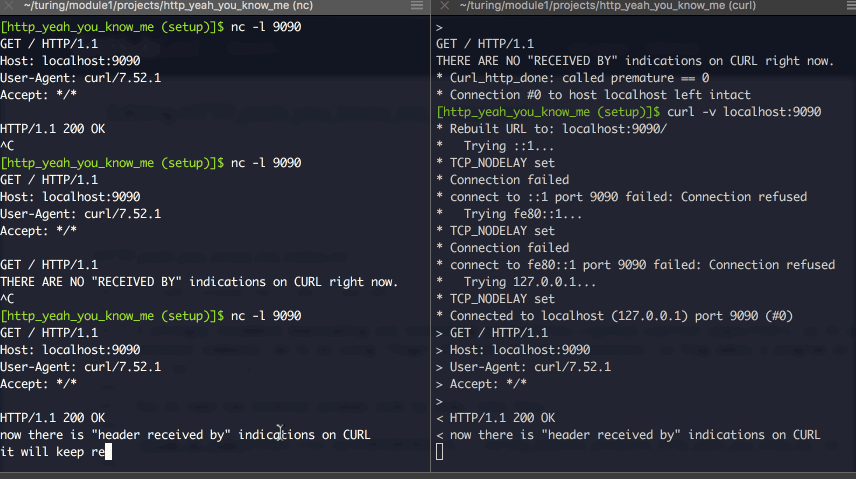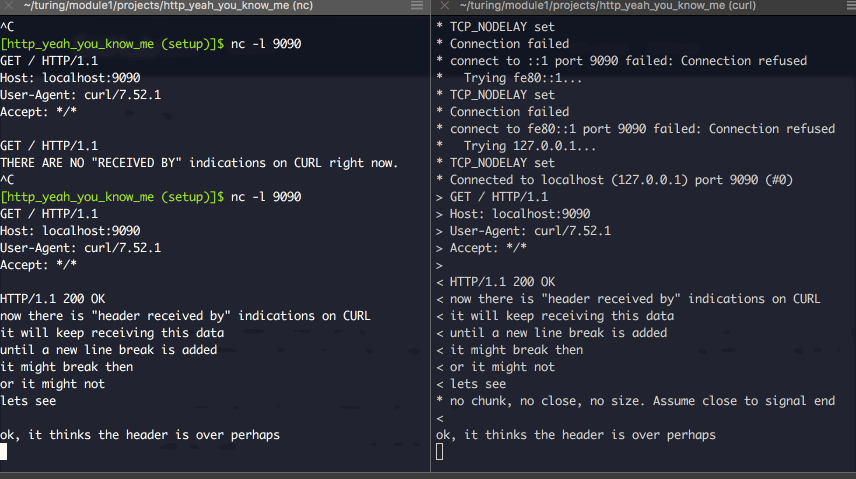
You can write, line by line, your own valid header. You’ll notice it ends whenever you add a new-line character, and when you DO try to send actual content, if you get the “content-length” figure wrong, it’ll cut you off.
example:
I want to talk to my ruby program now #
I feel lik I can use Netcat to impersonate a client (or server? still not sure) and talk to my ruby program (which is operating as a server…) So… lets do that.
Here’s the ruby I’m running:
require 'pry'
require 'socket'
class HTTP
attr_reader :server
def initialize
@server = TCPServer.new(9090)
end
puts "server's up, capiTAN"
def receive_request_send_response
while client = server.accept
whole_response = []
while line = client.gets and !line.chomp.empty?
whole_response << line
end
whole_response
end
output = "<html><head></head><body>holy what the fuck</body></html>"
end
end
p server = HTTP.new
p server.server
p server.receive_request_send_response
When I run the ruby program, it just hangs. Which means it’s stuck in while client = server.accept. When I run curl -v localhost:9090 it too just sits and waits. Everyone is waiting for a response, but not even a header is sent, else curl would have shown
> header data
> sent by
> curl
So, CURL doesn’t have anything to send to. I wonder why.
nc has an option. Checking out tldr nc the first option says:
Connect to a certain port (you can then write to this port): nc ip_address port
Good enough for me.
nc localhost 9090 doesn’t do anything in either the ruby program or NC.
Lets try submitting a well-formatted HTTP request, and see what happens
I tried typing in exactly what CURL had sent last time:
> GET / HTTP/1.1
> Host: localhost:9090
> User-Agent: curl/7.52.1
> Accept: */*
and got nothing. but that’s OK, cuz my program (right now) isn’t showing me the captured HTTP request. Lets modify it to do that.
…
…
still trying to get this to work. Rolling back to a “known good” state w/my ruby program that captures server data.
Oh, worth noting:
if you see something that has this:
GET / HTTP/1.1
What is it? A request or a response?
How about this:
HTTP/1.1 200 OK
The first one is a request, the latter a response. I’m starting to not confuse them.
Boom, did it. First, I rolled back to the “server” we wrote as part of the tutorial I linked above.
require 'socket'
tcp_server = TCPServer.new(9292)
client = tcp_server.accept
puts "ready for a request"
request_lines = []
while line = client.gets and !line.chomp.empty?
request_lines << line.chomp
end
puts "I (the server) just got this request:"
puts request_lines.inspect
puts "I (the server) am sending response."
response = "<pre>" + request_lines.join("\n") + "</pre>"
output = response
headers = ["http/1.1 200 ok",
"date: #{Time.now.strftime('%a, %e %b %Y %H:%M:%S %z')}",
"server: ruby",
"content-type: text/html; charset=iso-8859-1",
"content-length: #{output.length}\r\n\r\n"].join("\r\n")
client.puts headers
client.puts output
puts ["Wrote this response:", headers, output].join("\n")
client.close
puts "\nResponse complete, exiting."
I started that, and then in a different tab ran nc localhost 9292 (please note I’m mixing up some port numbers here, so don’t just copy/paste and expect any of this to work.)
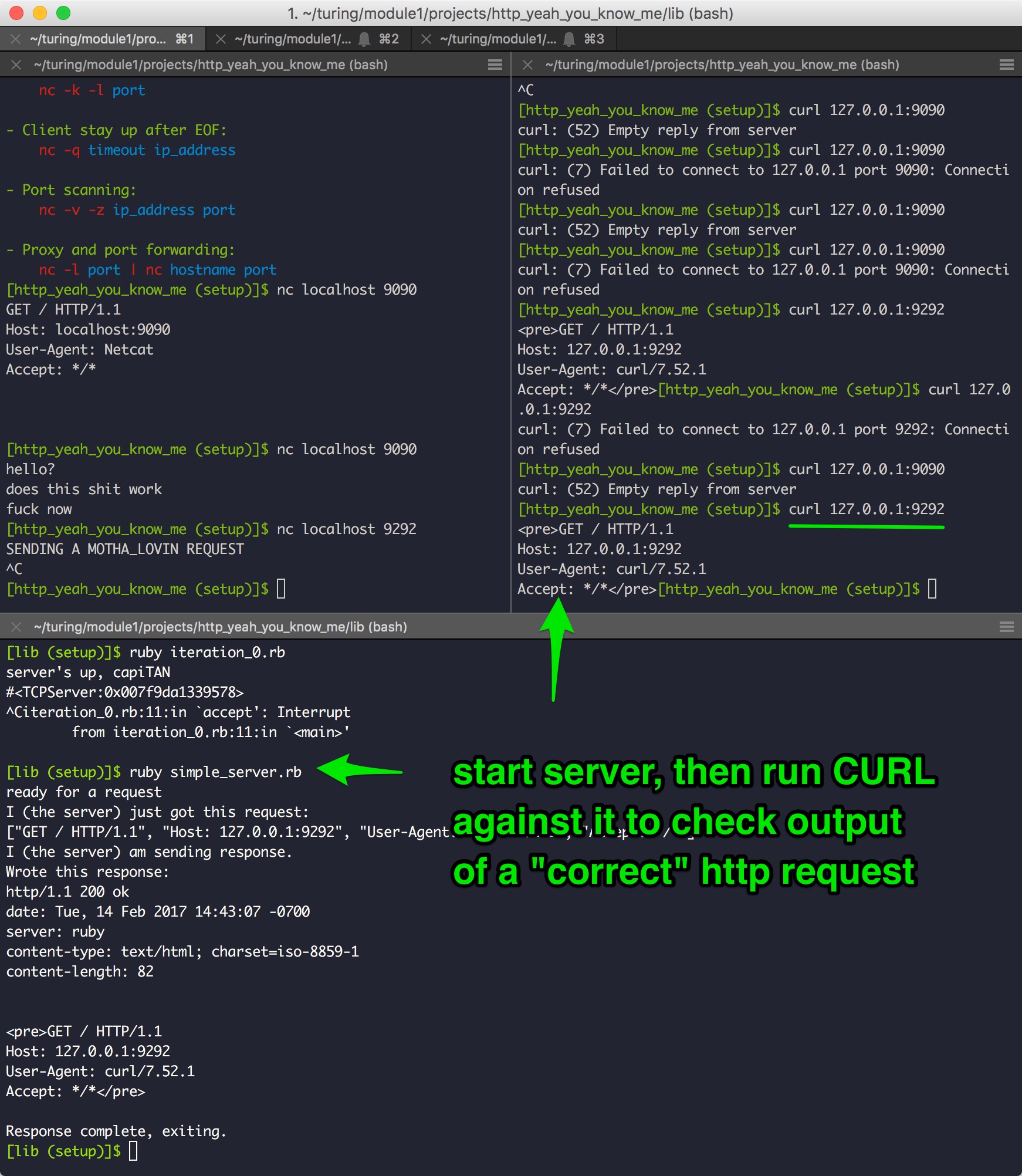
So, now the server will capture correctly-formatted HTTP requests and print them. Now lets build our own HTTP request in Netcat
Aww, yeah. Got it working. Check it out:
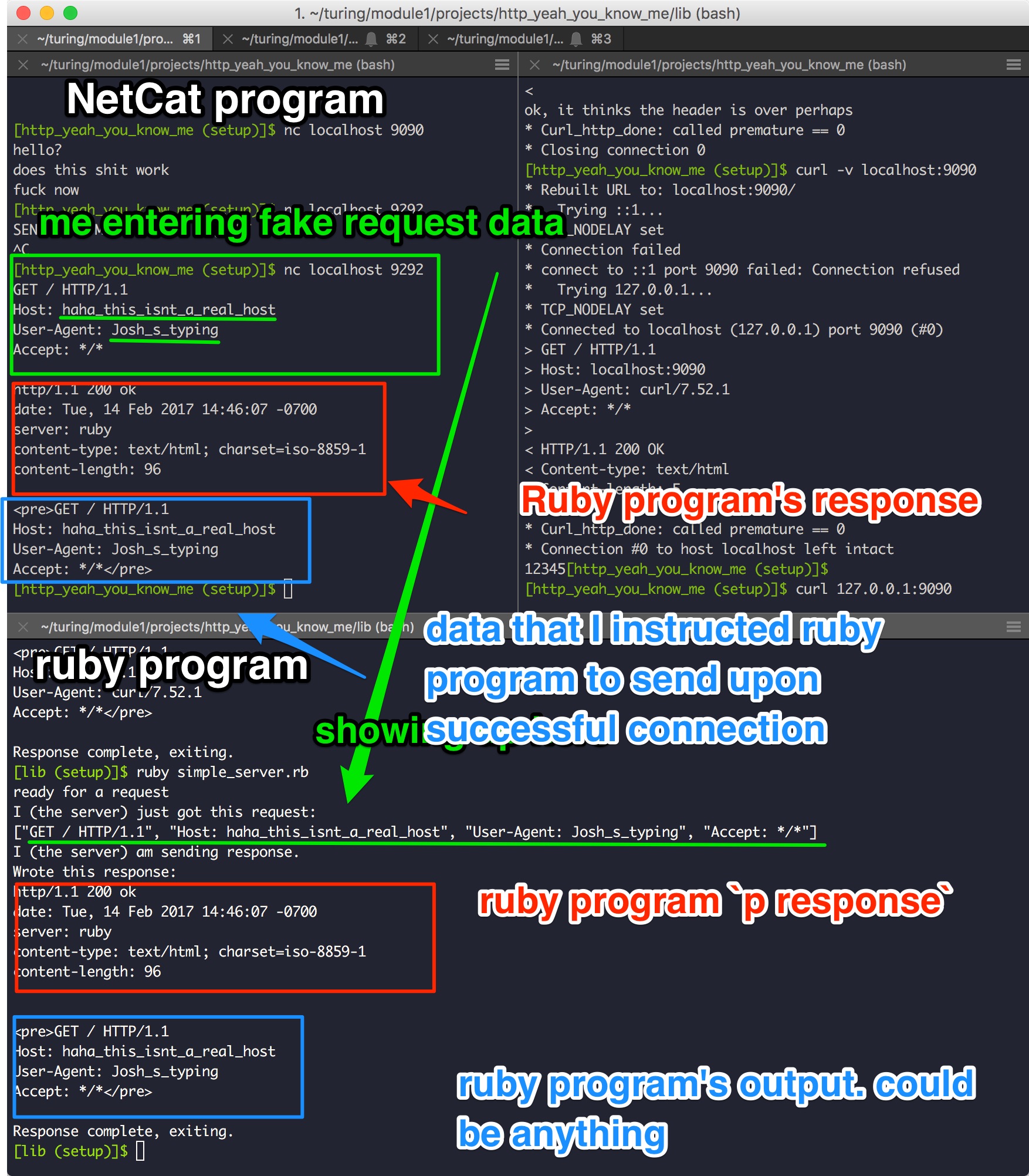
I’m slowly (very slowly) building a mental map of what’s going on behind the scenes, but this feels like a good realization.
Back to the class project and iteration 0 #
So we now know exactly what this is doing:
while line = client.gets and !line.chomp.empty?
request_lines << line.chomp
end
It’s taking in header data from the client making the HTTP request, and ONLY header data. As soon as it gets a blank line (which is the universal sign for “end of header data”) it stops adding new lines to the header data.
I’m restarting at Iteration 0, but this time putting everything in a class and methods. I’m not testing yet, that’ll come later.
I’ve also not touched Faraday. ¯_(ツ)_/¯
OK, got Iteration working, inside of a class:
require 'pry'
require 'socket'
class HTTP
attr_reader :server
attr_accessor :client_response, :counter
def initialize
@server = TCPServer.new(9090)
@client_response = []
@counter = 0
end
# note to myself in terminal when this gets hit.
puts "server's up, capiTAN"
def send_message
while client = server.accept
while line = client.gets and !line.chomp.empty?
client_response << line = line.chomp
end
# assign a big block of text to a string with %{text}. New lines get \n auto-added
output = %{<html><head></head><body>
#{client_response.join("\n")}
this server has been (re)started #{counter} times
</body></html>\n}
headers = [
"HTTP/1.1 200 OK",
"date = #{Time.now.strftime("%Y-%B-%d, %l:%M %P")}",
"server: ruby",
"content-type: text/html; charset=UTF-8",
"content-length: #{output.length}",
"\r\n"
]
client.puts headers
client.puts output
@counter += 1
end
end
end
my_server = HTTP.new
my_server.send_message
I can hit it in Postman or with CURL, and everything is expected. It’s ugly, but damnit, it works.
Iteration 1 #
I’m thinking I just need to add the HTML <pre></pre> tags to pretty-format the returned text.
require 'pry'
require 'socket'
class HTTP
attr_reader :server
attr_accessor :client_response, :counter
def initialize
@server = TCPServer.new(9090)
@client_response = []
@counter = 0
end
# note to myself in terminal when this gets hit.
puts "server's up, capiTAN"
def send_message
while client = server.accept
while line = client.gets and !line.chomp.empty?
client_response << line = line.chomp
end
# assign a big block of text to a string with %{text}. New lines get \n auto-added
output = %{<html><head></head><body>
<pre>#{client_response.join("\n")}</pre>
this server has been (re)started #{counter} times
</body></html>\n}
headers = [
"HTTP/1.1 200 OK",
"date = #{Time.now.strftime("%Y-%B-%d, %l:%M %P")}",
"server: ruby",
"content-type: text/html; charset=UTF-8",
"content-length: #{output.length}",
"\r\n"
]
client.puts headers
client.puts output
@counter += 1
end
end
end
my_server = HTTP.new
my_server.send_message
When I do this, my @client_response array gets longer… and longer… and longer. because everytime I reload the server I re-add new diagnostic info to it. So, lemme fix that.
Now, I’m having trouble getting the server to recognize the end of the header and the content.
The problem is with my new-line characters in my header response, I believe.
Editing my headers to:
headers = ["HTTP/1.1 200 OK\r\n" +
"date = #{Time.now.strftime("%Y-%B-%d, %l:%M %P")}\r\n" +
"server: ruby\r\n" +
"content-type: text/html; charset=UTF-8" +
"content-length: #{output.length}" +
"\r\n\r\n"
]
and we’re almost back in action. Here’s the CURL output:
[http_yeah_you_know_me (setup)]$ curl -v localhost:9090
* Rebuilt URL to: localhost:9090/
* Trying ::1...
* TCP_NODELAY set
* Connection failed
* connect to ::1 port 9090 failed: Connection refused
* Trying 127.0.0.1...
* TCP_NODELAY set
* Connected to localhost (127.0.0.1) port 9090 (#0)
> GET / HTTP/1.1
> Host: localhost:9090
> User-Agent: curl/7.52.1
> Accept: */*
>
< HTTP/1.1 200 OK
< date = 2017-February-14, 5:22 pm
< server: ruby
< content-type: text/html; charset=UTF-8content-length: 215
* no chunk, no close, no size. Assume close to signal end
<
<html><head></head><body>
<pre>GET / HTTP/1.1
Host: localhost:9090
User-Agent: curl/7.52.1
Accept: */*</pre>
this server has been (re)started 0 times
</body></html>
It thinks the content ended before the last line. (see how content-length: 215 is directly following content-type? lets add an \r\n to the end of that line in my Header output.
updated headers to:
headers = ["HTTP/1.1 200 OK\r\n" +
"date = #{Time.now.strftime("%Y-%B-%d, %l:%M %P")}\r\n" +
"server: ruby\r\n" +
"content-type: text/html; charset=UTF-8\r\n" +
"content-length: #{output.length}\r\n" +
"\r\n"
]
and it works! Iteration 1 done.
Iteration 2: supporting paths #
well eff, my existing code is so horrible path support is a major PITA.
Part of the problem is I cannot easily calculate my output length, so building my response, I cannot tell the server (easily) how many characters to expect.
Time for some refactoring, I guess.
I’m going to try to clean up my http response block. Here’s what I’ve got:
helloworld_path = ["<html><head></head><body>" +
"hello world, this has been reloaded #{counter} times." +
"</body></html>"]
@counter += 1
default_path = ["<html><head></head><body>\r\n" +
"<pre>#{client_response.join("\n")}</pre>\r\n" +
"this server has been (re)started #{counter} times\r\n" +
"</body></html>\n"
]
headers = ["HTTP/1.1 200 OK\r\n" +
"date = #{Time.now.strftime("%Y-%B-%d, %l:%M %P")}\r\n" +
"server: ruby\r\n" +
"content-type: text/html; charset=UTF-8\r\n" +
"content-length: #{helloworld_path.join.length}\r\n" +
"connection: close" +
"\r\n\r\n"
]
client.puts headers
notice I’ve hard-coded “helloworld_path”. That’s because trying to add path support revealed this little problem to me.
.
.
.
It’s a PITA, but… a few hours of work after ^^, I sorted it out. There’s a few pieces in play:
- Pulling data from the GET request (like path)
- building the FRAME if the server response. Hardcode some pieces, use variables for the stuff that changes
- Build variables that hold the variable parts of the response. (seems obvious, right? That’s why I wanna smash through my desk with my head.)
I’ll add comments to the following code. This mostly handles iteration 2:
def send_message
# client_response holds all the received data, like `GET / HTTP/1.1`. The / is of particular interest.
client_response = []
while client = server.accept
while line = client.gets and !line.chomp.empty?
client_response << line = line.chomp
end
# ^^ end of building the client response
# pulling out the path, be it /, or /hello, or /datetime, etc.
path = client_response[0].split[1]
# building variables to insert into my HTTP response block later
time = Time.now.strftime("%Y %B %d, %H:%M %z")
# possible responses based on path
hello_path = ["hello world, this has been reloaded #{counter} times."]
default_path = ["<pre>#{Time.now}\nThis is my default path</pre>\r\n"]
datetime_path = ["<pre>The time is #{time}</pre>"]
shutdown_path = ["Total requests: #{counter}\nExiting..."]
if path == "/"
response = default_path
elsif path == "/hello"
response = hello_path
elsif path == "/datetime"
response = datetime_path
elsif path == "/shutdown"
response = shutdown_path
end
# building the server response. It'll always get wrapped the the following HTML. the `join` method fixes the fact that the parameters are currently wrapped in brackets. example: hello_path = ["some string here"])
output = "<html><head></head><body>#{response.join}</body></html>"
# this is the fixed part of the server response. Every response will be the same, except the date changes to be Time.now, and output.length MUST be accurate, or the server will either not print the full request, or it'll hang after all the data is received, because it's expecting more.
headers = ["http/1.1 200 ok",
"date: #{time}",
"server: ruby",
"content-type: text/html; charset=iso-8859-1",
"content-length: #{output.length + 1}\r\n\r\n"].join("\r\n")
# incrementing my counter
@counter += 1
# client.puts is the _sending_ actual response to the server. Headers is distinct from the output.
client.puts headers
client.puts output
# this stuff is sorta ugly random shit to reset the values so when I reload the page, it'll accept different paths. I am 100% sure this is not best practice.
client.close
# I couldn't get my shutdown method to sit neatly in one if statement. ¯\_(ツ)_/¯
client.exit if path == "/shutdown"
# resetting values for next connection
response = nil
path = nil
client_response = []
end
end
end
my_server = HTTP.new
my_server.send_message
Iteration 3: supporting params #
Given a sample paramter like
http://host:port/path?param=value¶m2=value2
how can we pull the parameters? That will be the first step to doing something with them. I don’t care how I store them for now.
I think I can pull everything following the ? using a REGEX match or split or something.
lets play around in pry with the string.
string = "http://host:port/path?param=value¶m2=value"
# eff, so confused.
# ok, I used this:
path = client_response[0].split[1]
word_search = path.split("=")[1]
here’s the output from pry:
path ... "/word_search?word=house"
response ... nil
shutdown_path ... nil
time ... nil
word_search ... "house"