👋
This spot on the internet functions as a scratch pad, mostly for myself, and obviously anyone who finds themselves reading anything here.
While you’re here, tell me…
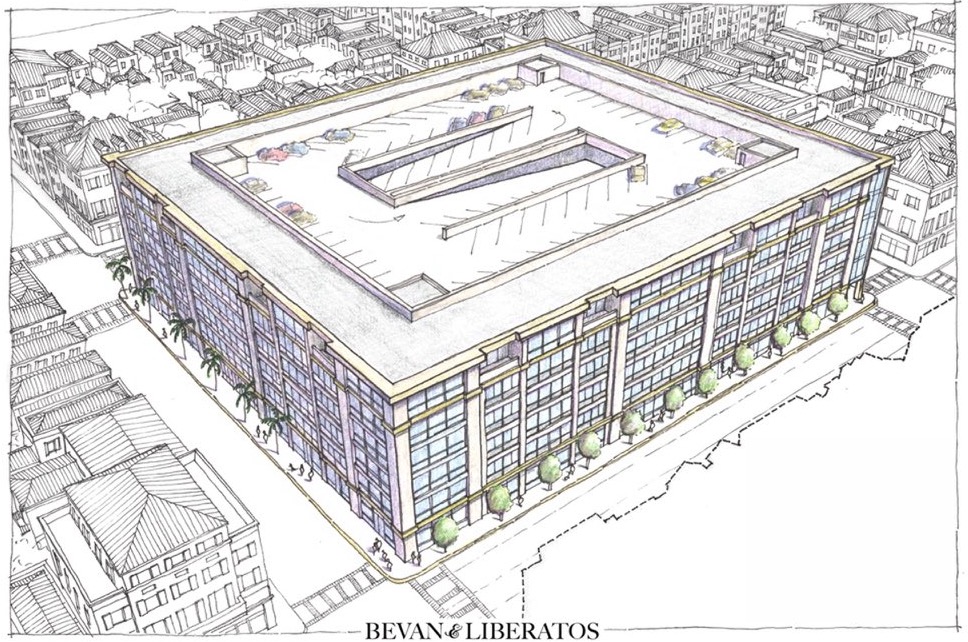
for so many reasons, this sort of pattern abounds, right? Is this sorta familiar?
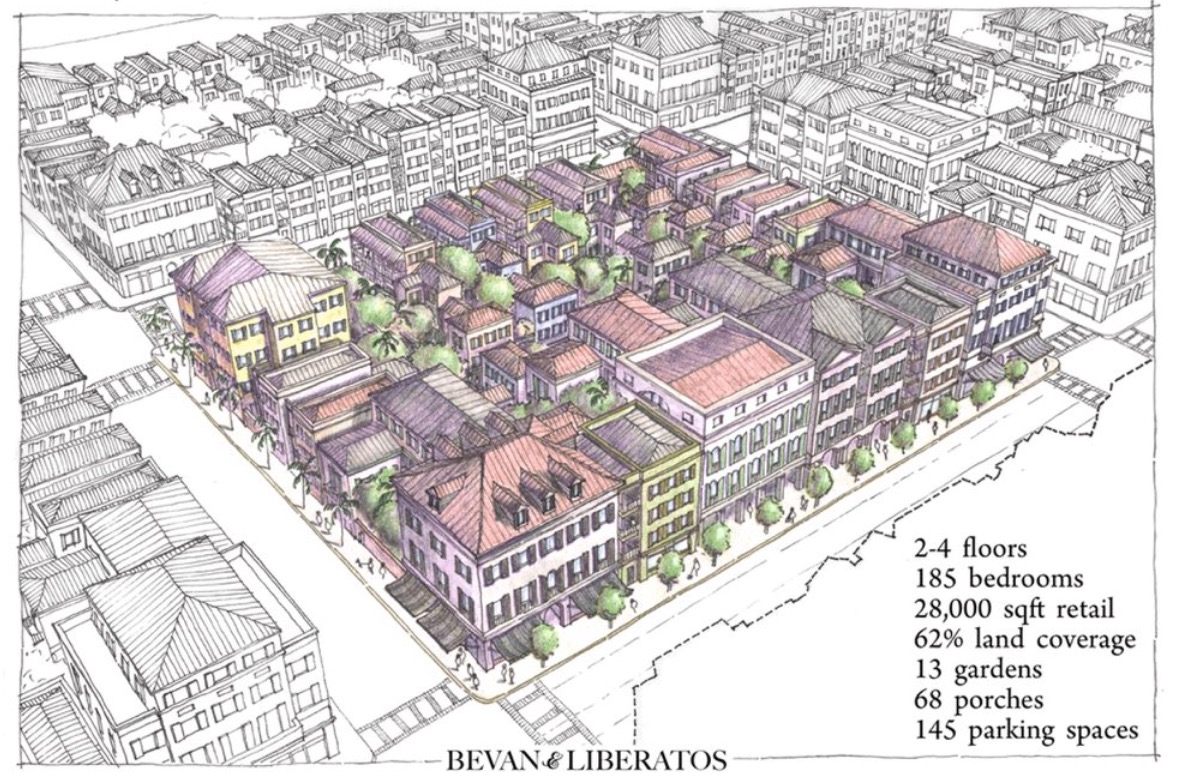
we’d all be better off seeing instead something like this, perhaps?
One last thing to consider. The lines represent paths, across streets, taken by the people who live along those streets, in various conditions:
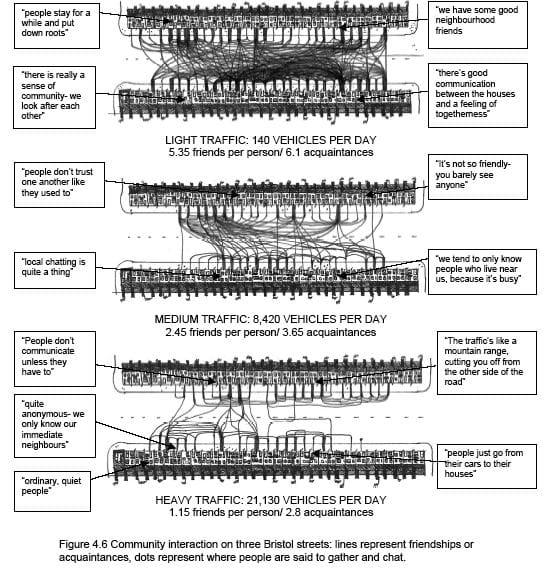
Which one would you want to live near?
I know which one I’d want.
Click over to the blog for more, I suppose.
Want to stay up to date on these projects? Enter your email below, and you'll get an approximately-monthly newsletter from me.
Footnotes/Misc #
I cannot help but draw attention to work of Urban Economists Marie-Agnes Bertaud & Alain Bertaud. They wrote Order Without Design: and this paper.
The paper, efficiency in land use and infrastructure design: an application of the Bertaud Model, is hot reading, but completely unavailable in a land controlled by american-style zoning laws and embedded within american-style mobility networks.
His paper, explains something like one could use desired cost per finished square square foot as an input to a function/process for creating housing and space. Look at page 14 of the PDF.
The concept of “minimum consumption requirements” in any sort of housing regime destroys the possibility of good-enough land use. (america is full of minimums, not just parking minimums. ‘consumption minimums’ was the original goal of ‘euclidean’ zoning (supremacist housing policy) that is still wrapped around land use like a mycelial network wrapped around and throughout a block of cheese.).
one could wonder:
If not ‘euclidean’/american-style/supremacist zoning paradigms, what else?
Christopher Alexander formalized the concept of design patterns which can be applied helpfully to many different “sized” physical space ‘problems’.
He’s the author of A Pattern Language: Towns, Buildings, Construction, and identifying this approach for problem solving has consistently been interesting-enough and effective-enough for me, at least some of the time.