Rails Migration: When you can't add a uniqueness constraint because you already have duplicates
Article Table of Contents
- This post has been updated to reflect some lessons learned while running this migration in production. Don’t leave a column without an index at any point in the migration. skip to section
- What’s the easy fix?
- Limit count, offset
I get to occasionally contribute to the Wombat Security dev blog. I wrote the following for development.wombatsecurity.com.
This post has been updated to reflect some lessons learned while running this migration in production. Don’t leave a column without an index at any point in the migration. skip to section #
For work, I picked up a bug where a CSV export was creating duplicate rows when it shouldn’t have been.
We generate the CSV export with a big ol’ SQL statement in some Elixir workers, and got the bug reproduced and found the problem was with how we did some joins on other columns.
We had something in the statement like this:
LEFT OUTER JOIN `reports` ON `reports`.`id` = `people`.`report_id`
LEFT JOIN `addresses` ON `addresses`.`people_id` = `people`.`id`
LEFT JOIN `favorite_colors` ON `favorite_colors`.`people_id` = `people.id`
In this highly contrived example, I found out that we’re expecting a single row in the favorite_colors table for each person, but we were getting multiple favorite_color rows.
Every time we had a duplicate row on that joined table, the LEFT JOIN created two rows in the export, even though there should have been one.
Thoughtbot has an amazing article about the exact problem we were having.
In that article, they describe the problem with uniqueness validations like so:
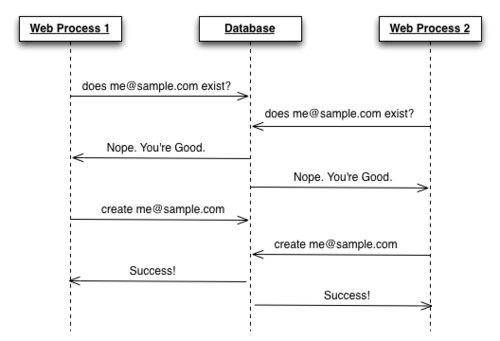
https://robots.thoughtbot.com/the-perils-of-uniqueness-validations
We need to enforce uniqueness at the database level. Not the model level.
What’s the easy fix? #
The “easy” fix is simple - Add an index to the column you want to enforce uniqueness upon, then add a uniqueness constraint:
(since this column already happened to have an index in our database, we have to remove it and re-add it in the migration)
class AddUniquenessConstraintToFavoriteColors < ActiveRecord::Migration
def change
remove_index :favorite_colors, :person_id
add_index :favorite_colors, :person_id, unique: true
end
end
Lets make this a bit more explicit. We’ll define an up and down migration. (you’ll see why in a moment)
Up/down migration #
I am going to be explicit about the up and down, for the rollback:
class AddUniquenessConstraintToFavoriteColors < ActiveRecord::Migration
def up
remove_index :favorite_colors, :person_id
# you can't MODIFY the index, just remove it, then re-add it with the changes
add_index :favorite_colors, :person_id, unique: true, algorithm: :inplace
# unique forces uniqueness (duh)
end
def down
remove_index :favorite_colors, :person_id
# removing the index that has uniqueness constraint
add_index :favorite_colors, :person_id
# adding one without the constraint
end
end
This migration will work, if you run it against a table that doesn’t have duplicate values in the given column.
But the whole reason I was digging into all this was because I had a table with duplicate values. This is a table that now has many rows of data, and more than a few duplicates.
If you run the above migration, and there are duplicates on the table, you’ll get a lovely error like so:
== 20180914203948 AddUniquenessConstraintToFavoriteColors: migrating ========================
-- remove_index(:favorite_colors, :person_id)
-> 0.0388s
-- add_index(:favorite_colors, :person_id, {:unique=>true, :algorithm=>:inplace})
rake aborted!
StandardError: An error has occurred, all later migrations canceled:
Mysql2::Error: Duplicate entry '44' for key 'index_favorite_colors_on_person_id': CREATE UNIQUE INDEX `index_favorite_colors_on_person_id` ON `favorite_colors` (`person_id`) ALGORITHM = INPLACE
Clean up duplicates and add uniqueness constraint #
The big question was:
How do we clean up the duplicates, and run the migration, without duplicates showing up between when we clean them up and run the migration?
My first thought was a rake task to find and prune duplicates, but this is a relatively active table, and if even a few seconds elapsed between the rake task and migration, we might get another duplicate on it, which would prevent the migration from running.
The Solution #
The rake task was not a good solution. Fortunately, I work with many people who are much smarter than I, and they put me on the right track. I needed to update the migration to run a query that would:
- Find all duplicate rows
- Get the ID’s of those duplicate rows
- Trim one of the row IDs of the “duplicates” list
- Delete all the remaining IDs.
So, the SQL query gets built up in three pieces.
I’ll give you the full SQL query, then we’ll dig into the component pieces. The following query creates a list of IDs that we can then use ActiveRecord/Sequel to delete. (More on the migration in a minute):
SELECT substring(dups.id_groups, position(','IN dups.id_groups) + 1)
FROM
(SELECT group_concat(fc.id) AS id_groups
FROM favorite_colors fc
WHERE EXISTS
(
SELECT 1
FROM favorite_colors tmp
WHERE tmp.person_id = fc.person_id
LIMIT 1, 1
)
GROUP BY fc.person_id
) AS dups
Lets unpack it. First, here’s a little SQL you could run locally to generate results to play with:
CREATE TABLE favorite_colors (
ID INT AUTO_INCREMENT PRIMARY KEY ,
person_id INT,
color VARCHAR(255)
);
INSERT INTO `favorite_colors` (`ID`, `person_id`, `color`)
VALUES
(1, 1, 'yellow'),
(2, 1, 'yellow'),
(3, 2, 'blue'),
(4, 2, 'blue'),
(5, 3, 'green'),
(6, 2, 'purple'),
(7, 3, 'yellow'),
(8, 4, 'black');
OK, first, lets find the duplicate rows. There’s a lot of them in here. The following query comes from StackOverflow, and served me well:
SELECT *
FROM favorite_colors fc
WHERE EXISTS
(
SELECT 1
FROM favorite_colors tmp
WHERE tmp.person_id = fc.person_id
LIMIT 1, 1
)
ORDER BY fc.person_id
So, obviously, that WHERE EXISTS piece is interesting. But that depends on the SELECT 1... LIMIT 1, 1, which is unfamiliar to me.
Limit count, offset #
SELECT 1
FROM favorite_colors
LIMIT 1, 1
This is the most basic version of the above statement. The SELECT piece just inserts a 1 in the table. It could easily be SELECT "FOOBAR". The prior WHERE EXISTS is just looking for a value from the statement.
The LIMIT 1, 1 is curious. It’s LIMIT <count> <offset>. So it’s limiting the count to one, and it’s offsetting it by 1. PostgreSQL has the best docs on this function.
This means it returns one row, offset from the first row by 1. So, if you ran the following query:
SELECT *
FROM favorite_colors
LIMIT 2, 4
You’d get four rows, skipping the first two rows, and including the subsequent four.
Here’s the results of:
SELECT *
FROM favorite_colors
LIMIT 2
| id | person_id | color |
|---|---|---|
| 1 | 1 | yellow |
| 2 | 1 | yellow |
And if we run
SELECT *
FROM favorite_colors
LIMIT 2, 2
we get:
| id | person_id | color |
|---|---|---|
| 3 | 2 | blue |
| 4 | 2 | blue |
So, LIMIT 1, 1 takes the results of the prior WHERE and basically “hides” the first match, and leaves only the second match. The temporary result would be empty when the EXISTS statement checked the subquery, and the row would be deemed “not a duplicate”.
EXISTS #
In the docs, we learn:
If a subquery returns any rows at all, EXISTS subquery is TRUE, and NOT EXISTS subquery is FALSE. For example:
SELECT column1 FROM t1 WHERE EXISTS (SELECT * FROM t2);
I still don’t fully grasp the nuance of the total SQL statement, but I feel like I’m approaching comprehension. Either way, I am pleased to know how to return the complete rows of duplicates from a table where there are duplicate values in a given column.
OK, so we’ve got duplicates. How do we make them usable?
Get IDs from results #
We don’t want to SELECT *, now, we want to SELECT group_concat(favorite_colors.id) AS id_groups.
SELECT group_concat(fc.id) AS id_groups
FROM favorite_colors fc
WHERE EXISTS
(
SELECT 1
FROM favorite_colors tmp
WHERE tmp.person_id = fc.person_id
LIMIT 1, 1
)
GROUP BY fc.person_id
returns:
| id_groups |
|---|
| 1,2 |
| 3,4,6 |
| 5,7 |
The GROUP BY table.column_with_duplicates is important to split the groups by unique value. Without the group by, you’d get one long string of joined IDs, which would be totally useless.
Next, we want to trim off the first ID in each of these groups. So, here’s the full query:
SELECT substring(dups.id_groups, position(','IN dups.id_groups) + 1)
FROM (
SELECT group_concat(fc.id) AS id_groups
FROM favorite_colors fc
WHERE EXISTS
(
SELECT 1
FROM favorite_colors tmp
WHERE tmp.person_id = fc.person_id
LIMIT 1, 1
)
GROUP BY fc.person_id
) AS dups
And this returns:
| id_groups |
|---|
| 2 |
| 4,6 |
| 7 |
And the results of this SQL statement can now be deleted from the database via ActiveRecord. Here’s our full migration:
class AddUniquenessConstraintToFavoriteColors < ActiveRecord::Migration
disable_ddl_transaction!
def up
results = execute <<-SQL
SELECT substring(dups.id_groups, position(','IN dups.id_groups) + 1)
FROM
(SELECT group_concat(fc.id) AS id_groups
FROM favorite_colors fc
WHERE EXISTS
(
SELECT 1
FROM favorite_colors tmp
WHERE tmp.person_id = fc.person_id
LIMIT 1, 1
)
GROUP BY fc.person_id
) AS dups
SQL
results.each do |id_array|
# I know find_in_batches would normally be a better fit
FavoriteColors.where(id: id_array).delete_all
end
remove_index :favorite_colors, :person_id
add_index :favorite_colors, :person_id, unique: true, algorithm: :inplace
end
def down
remove_index :favorite_colors, :person_id
add_index :favorite_colors, :person_id
end
end
In Conclusion #
You can use this pattern to add a uniqueness constraint to a table that already has duplicate values. This will clean out duplicates, but leave original values, and will prevent additional duplicates from being written to the table.
In hindsight, this was a relatively straight-forward migration. I had not found any resource online that talked about the process of adding a uniqueness constraint if the table already had data that violated the constraint, so I hope that this write-up might help someone else in a similar spot.
Update: Do not leave a column without an index at any point in the migration #
I made a mistake in all this.
Take a look at what we ran:
results.each do |id_array|
# I know find_in_batches would normally be a better fit
FavoriteColors.where(id: id_array).delete_all
end
remove_index :favorite_colors, :person_id
add_index :favorite_colors, :person_id, unique: true, algorithm: :inplace
end
See how we remove an index, then add it?
This means if the migration fails while adding the new index, and we have to re-run the migration, we’re now executing the query without an index on the favorite_colors column.
If you’re doing a big ol’ query against a few hundred thousand rows of data, with the index, it’ll take a few seconds. Without the index, it could take… many minutes.
Here’s what you should do:
results.each do |id_array|
# I know find_in_batches would normally be a better fit
FavoriteColors.where(id: id_array).delete_all
end
# rename existing index
rename_index :favorite_colors, :favorite_colors_non_unique
# add the uniqueness index (if we didn't rename the existing index, we'd get an error saying "an index by this name already exists")
add_index :favorite_colors, :person_id, unique: true, algorithm: :inplace
# This line won't get run unless the above index has been successfully added. We're removing it by the name we've given it:
remove_index :favorite_colors_non_unique
end