Troubleshooting Chinese Character Sets in MySQL
Article Table of Contents
- Reproducing the bug - Reproduce on localhost?
- Where is the correct encoding being stripped/broken/lost/’misplaced’?
- Does our database support Chinese characters?
- Make sure that the database is actually using the desired character set
- Determine the hexadecimal value of the character or characters that are not being displayed correctly.
- Make sure that a round trip is possible. When you select
literal(or_introduce hexadecimal-value), do you obtainliteralas a result? - on a per-table basis, changing
character_set_name - Editing tables on a oneshot
- Rails migration for
character_set_name - Asking Jordan for help - Resources
A while back, I picked up a bug where when a customer tried to save certain kinds of data using Chinese characters, we were replacing the Chinese characters like 平仮名 with a series of ?.
This will be a quick dive through how I figured out what the problem was, and then validated said problem, and then what the actual fix is.
This isn’t just a story about character encoding, though. It’s a story about debugging. Debugging skills are valuable, and just like any other skill, they can be sharpened. I have built some competence in this domain, and I wanted to record some of the process, in the hopes that it might help others.
I perceive good debugging to go hand-in-hand with asking good questions. I wrote Asking experts, and gaining more than just answers about how asking good questions is hard, but done well makes it easy for someone else to help you, and leads to deeper understanding of the space.
Mark Dalrymple wrote Thoughts on Debugging, Part 1 and said:
Debugging, to me, is just a skill. It’s an analytical skill, but fundamentally it is a skill that can be learned and developed through practice: you identify problems, analyze the system to figure out what is causing that problem, and then figure out the changes necessary to correct the problem.
Finding the cause leads to the solution. The fix might not be practical from a business perspective. If fixing this bug requires overhauling the entire app, it might make better sense to leave it than to pay what it would take to fix.
Good debugging is also a particularly useful skill a developer could bring to their job, and you don’t have to be an experienced developer to be good at debugging. You could argue good debugging is based more on attitude than technical know-how, so if you’re just getting your start in the software development industry, making sure you’re good at debugging things and then telling potential employers this could be to your advantage.
Here’s some more thoughts on this, from other developers (quoted anonymously from the DenverDevs Slack channel):
For what it’s worth, I had most of this blog post written before even seeing these quotes.
dev_1:
There’s the tiresome old joke about “I’m not better at computers/coding/etc. than you, I’m just better at google!” Ha. So funny.
But a truly under-appreciated skillset that I think doesn’t get its fair share of mention from experts/teachers/celebrity-bloggers or attention by some developers is debugging.
There’s often so much mental headspace put into the idea of writing code, good code, functional code, that “what do I do when I don’t write working code” is rarely addressed.
Even well seasoned (yum) devs are constantly surprised by features of browser devtools, that
console.trace()exists alongsideconsole.log(), and more.I think it’s often seen as a side effect of what we do so much that we learn the tools and techniques as we need them instead of as a crucial skill.
I think making mistakes in your code and figuring out why the error/mistake is occurring is a great way to further comprehension of a language, don’t get me wrong. But so many people are never told where to look first when they don’t know why or how an error is occurring. They just feel like they’re going to a doctor and saying “it hurts” they don’t know where, they don’t know how, just, ouch.
dev_2:
I think also knowing where in a fullstack application, an error actually occurred is a super surprising and frankly awesome skill to see from someone more junior.
So being able to jump in, verify if a network request is showing you something funky, understanding what errors from different layers of the application might look at (depending on the error handling written at each level).
That is SUCH. A. GREAT. SKILL. Also a skill that will help you waste less and less time fumbling through errors as you develop.
Onward!
Note to the reader: this rest of this post is born out of notes I was making as I worked on this bug. I often create a document of notes based on the current Jira ticket I’m working on. Obviously that document isn’t fit for public consumption, so the following is a lightly editorialized version of this document, with modified screenshots, logs, etc.
Reproducing the bug #
Not all bugs can be reproduced. That makes them particularly challenging. But if a bug cannot be reproduced, that’s a bunch of useful signal in itself.
So, you need to determine if this bug can be replicated.
This particular bug happened to be very easily to replicate:
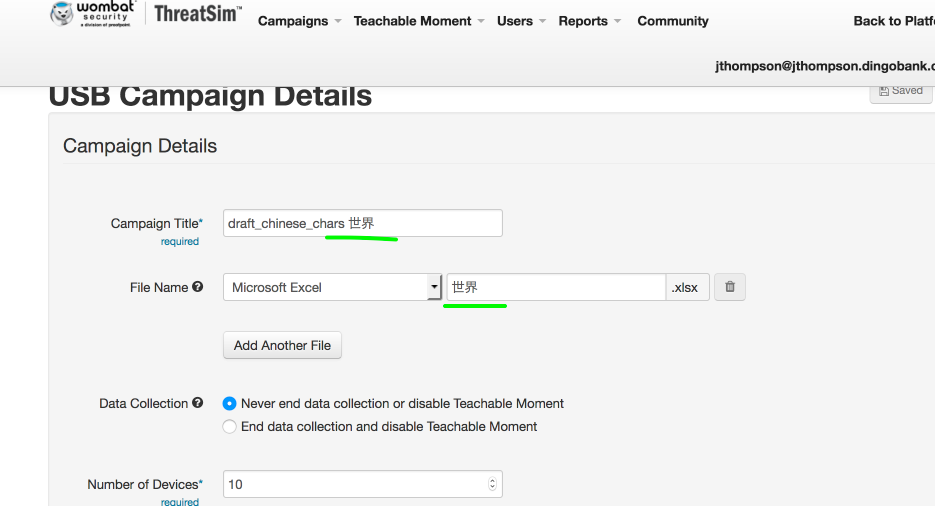
The results, after creating the campaign:
Reproduce on localhost? #
It’s one thing to find a bug happening on production - if one can then replicate it locally, that helps a lot. It’s easier to manipulate/examine state when running the app on your own machine, so now that I had this replicated “in the wild”, I re-did the same process on locally.
The encoding problem showed up just the same on my local machine.
So, now to see when and where we’re losing that character encoding.
Where is the correct encoding being stripped/broken/lost/’misplaced’? #
When building the campaign, can keep an eye on the network tab, and I see a POST request containing everything correctly encoded. (some params removed for readability):
{
"method":"POST",
"path":"/account/usb_campaigns/79",
"format":"json",
"controller":"account/usb_campaigns",
"action":"update",
"status":200,
"utf8":"\u2713",
"usb_campaign":{
----------------------------------------------------------------
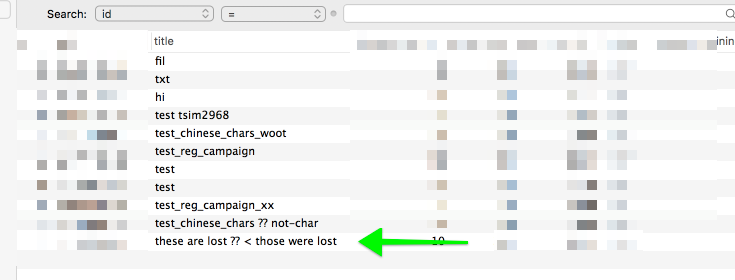
| "title":"these are lost \u4e16\u754c < those were lost", |
| # these characters following the `\u` encoded Chinese characters|
-----------------------------------------------------------------
"file_details_attributes":{
"0":{
"id":"7",
"nonce":"294033000",
"_destroy":"false",
"extension":"xlsx",
"basename":"chars.\u4e16\u754c.chars"
}
},
"device_quantity":"10",
"address_attributes":{
"id":"7",
"company_name":"ThreatSim Development",
"name":"f",
"street1":"f",
"street2":"",
"city":"f",
"country_code":"US",
"state":"GU",
"zip":"11111"
},
"id":"79"
},
"training_type_campaign_type":"USB"
}
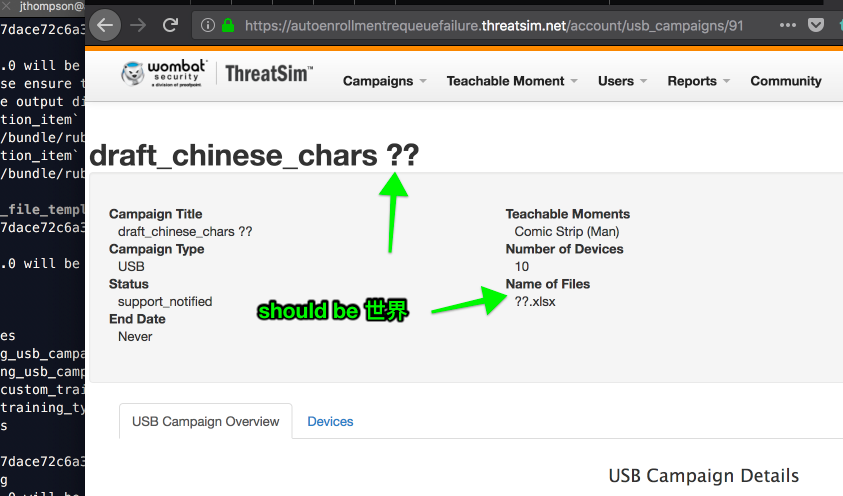
But when we take a look at the database, we’ve lost the encoding:
from the usb_campaigns table on localhost:
Ditto on the filename:
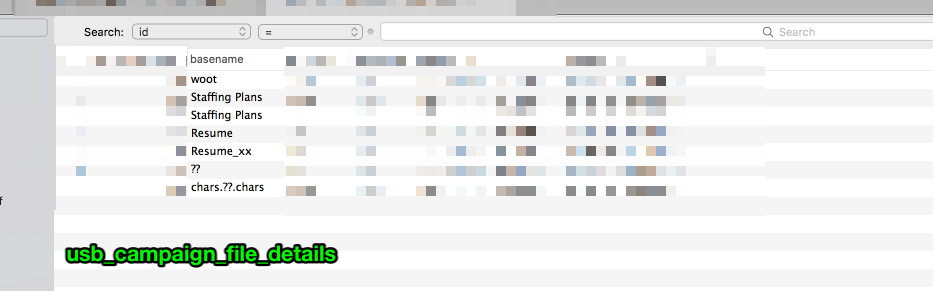
How do we store these values in the database? #
I’m first looking in the controller that this #update action hits:
def update
require "pry"; binding.pry
@campaign = current_user.account.usb_campaigns.find(params[:id]).decorate
authorize @campaign
saver.save
respond_with @campaign
end
Since I’m running this in localhost, I can just hit the pry and inspect the params. My params hash has everything as I expect it:
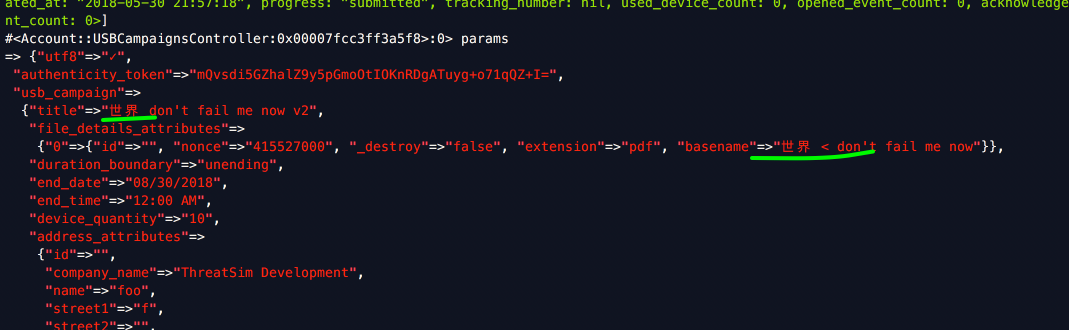
but if I play the line right under the require, and look at the object, it has lost the encoding:

So, why is Chinese encoding being lost? And where, precisely, is this object being built and modified?
Stepping through the method, line by line:
@campaign = current_user.account.usb_campaigns.find(params[:id]).decorate
Seems unrelated to saving the campaign. Just calls the decorator. Maybe to make sure that new values are captured next time someone looks at the campaign page?
authorize @campaign
no clue what it is doing. We have no def authorize in our app. Tons of references like authorize @custom_training, (about 122 instances) but can’t tell where it’s coming from. (Update: this is from the Devise gem)
saver.save
Now we’re getting somewhere. This line calls another method in our class (Account::USBCampaignsController in case you forgot… I just did.)
def saver
@saver ||= USBCampaign::Saver.new(campaign, draft?, usb_campaign_params, end_at_params, request.remote_ip)
end
And, this new USBCampaign::Saver object of course has #save available to it:
def save
EndDateParser.new(campaign, **end_at_params.symbolize_keys).parse!
campaign.assign_attributes(usb_campaign_params)
if campaign.may_draft? && saving_draft
campaign.draft!
elsif campaign.may_submit? && !saving_draft
if campaign.submit!
notify_support_of_new_usb_campaign!
end
else
campaign.save
end
end
If we dig into that second line, the usb_campaign_params are the expected values containing chinese characters, and assign_attributes is the standard way to update database values.
here’s the params going into the assign_attributes function:
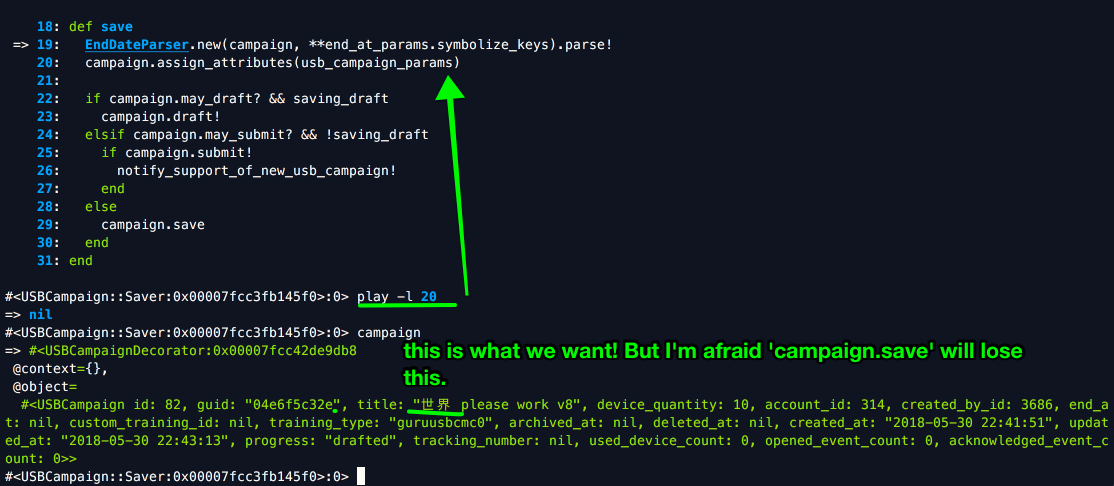
hm. campaign.save worked. I didn’t expect it to:

Lets check the database.
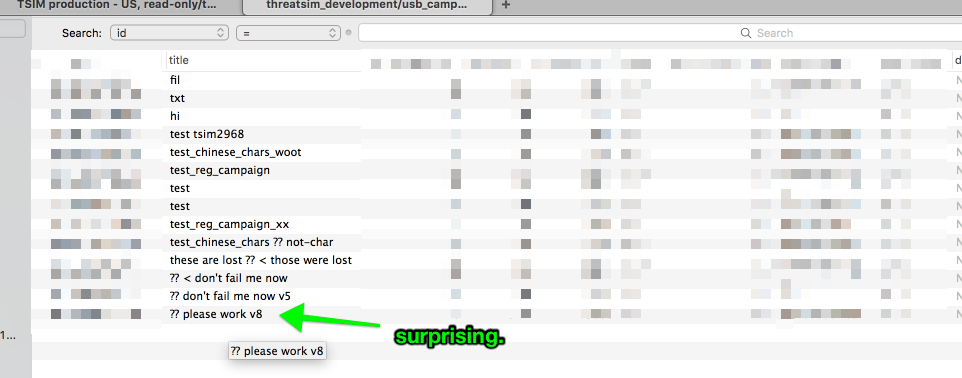
So why is my new object showing the wrong values?
AHA! campaign.reload for the win. I hadn’t pulled in new values from the DB, which seemed to fail to save correctly.

So, my working assumption at this point: We’re passing the correct information to the database when saving a new object, but the database itself is losing important information.
This leads to some obvious questions.
Does our database support Chinese characters? #
First, does our database support “unusual” characters? here’s my super sophisticated, professional-level test:
So, there’s one set of character encoding. Lets try Japanese characters:
Ah, interesting. I tried to paste in:
Hiragana. Hiragana (平仮名, ひらがな, Japanese pronunciation: [çiɾaɡana]) is a Japanese syllabary,
and got:

This looks suspiciously like our problematic Chinese characters:
世界
OK, the problem is how MySql handles these character sets.
Fortunately, the internet exists.
Here’s what I’m looking through for inspiration:
- php: Can’t insert Chinese character into MySQL
- MySQL 8.0 FAQ: MySQL Chinese, Japanese, and Korean Character Sets
From the MySQL docs, some notes as I follow their instructions:
First, CLI access to mysql running on docker:
mysql -h 127.0.0.1 -P 3306 -u root -p
mysql> SELECT VERSION();
+-----------+
| VERSION() |
+-----------+
| 5.6.38 |
+-----------+
Make sure that the database is actually using the desired character set #
SELECT character_set_name, collation_name
FROM information_schema.columns
WHERE table_schema = 'threatsim_development'
AND TABLE_NAME = 'usb_campaigns'
AND COLUMN_NAME = 'title';
gives:
+--------------------+-------------------+
| character_set_name | collation_name |
+--------------------+-------------------+
| latin1 | latin1_swedish_ci |
+--------------------+-------------------+
1 row in set (0.00 sec)
SELECT HEX('title')
FROM usb_campaigns;
Determine the hexadecimal value of the character or characters that are not being displayed correctly. #
gives:
+--------------+
| HEX('title') |
+--------------+
| 7469746C65 |
| 7469746C65 |
| 7469746C65 |
| 7469746C65 |
| 7469746C65 |
| 7469746C65 |
| 7469746C65 |
| 7469746C65 |
| 7469746C65 |
| 7469746C65 |
| 7469746C65 |
| 7469746C65 |
| 7469746C65 |
| 7469746C65 |
+--------------+
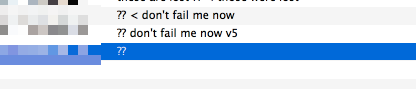
Make sure that a round trip is possible. When you select literal (or _introduce hexadecimal-value), do you obtain literal as a result? #
SELECT 'ペ' AS `ペ`;
returns:
?
This seems noteworthy.
And:
SELECT '世界' AS `世界`;
returns:
??
The plot thickens:
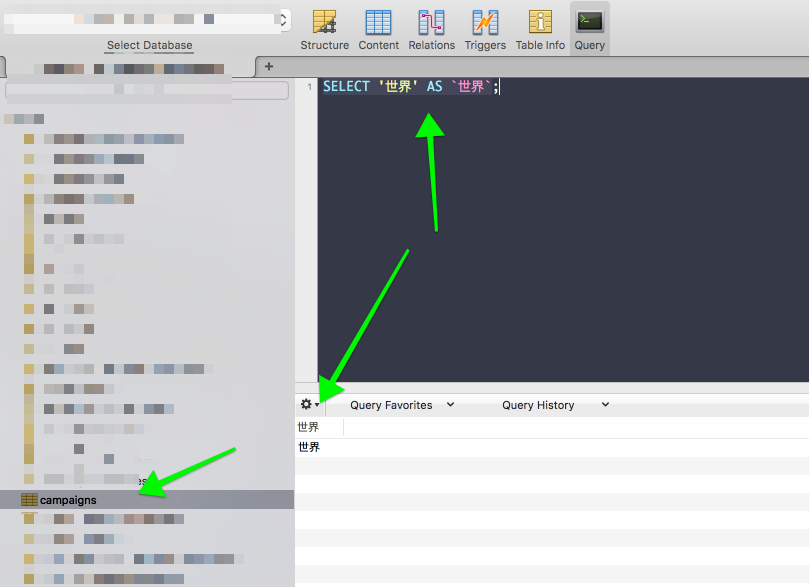
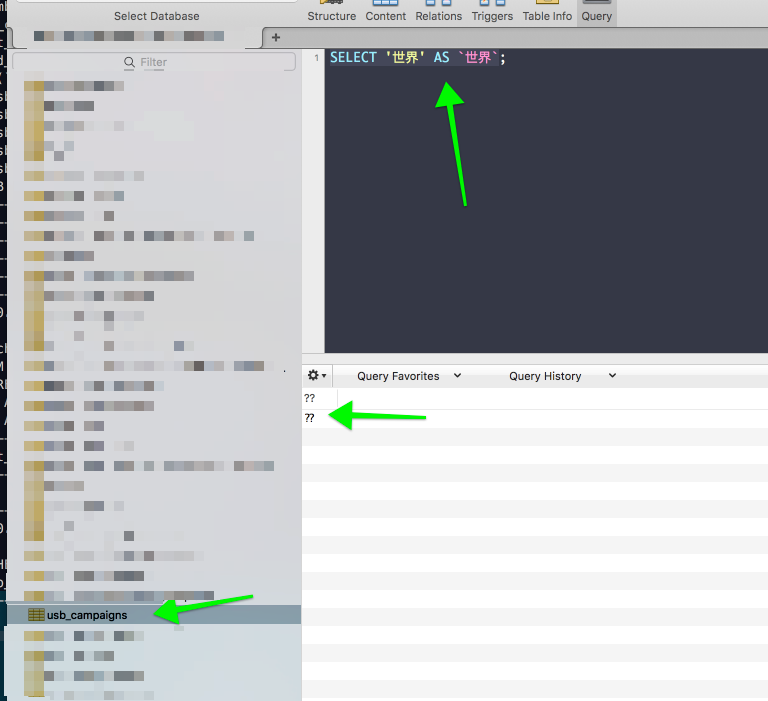
OK, it’s a per-table encoding problem. Our campaigns table can handle these values just fine, but not usb_campaigns:
on a per-table basis, changing character_set_name #
Lets compare a table where these character encodings work (campaigns) to where they don’t (usb_campaigns):
SELECT character_set_name, collation_name
FROM information_schema.columns
WHERE table_schema = 'threatsim_development'
AND TABLE_NAME = 'campaigns'
AND COLUMN_NAME = 'title';
gives:
+--------------------+--------------------+
| character_set_name | collation_name |
+--------------------+--------------------+
| utf8mb4 | utf8mb4_unicode_ci |
+--------------------+--------------------+
Remember that usb_campaigns gave:
+--------------------+-------------------+
| character_set_name | collation_name |
+--------------------+-------------------+
| latin1 | latin1_swedish_ci |
+--------------------+-------------------+
I bet if we changed the table encoding method, we’d be good to go!
Stackoverflow for the win. Suggested:
ALTER TABLE Table CONVERT TO CHARACTER SET utf8 COLLATE utf8_unicode_ci;, which I changed to:
ALTER TABLE threatsim_development.usb_campaigns
CONVERT TO CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
And now, when I check the character_set_name, I get:
+--------------------+--------------------+
| character_set_name | collation_name |
+--------------------+--------------------+
| utf8mb4 | utf8mb4_unicode_ci |
+--------------------+--------------------+
Wahoo!
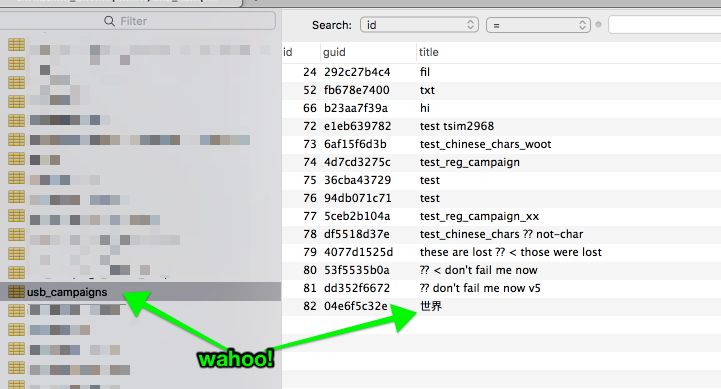
Editing tables on a oneshot #
So, lets sanity-check this in the app. If it works, I’ll update the table where we’re having the file_names problem too, and then I’ll figure out how to change this in production.
Wahoo! It works. I updated usb_campaigns and usb_campaign_file_details, and all is groovy:
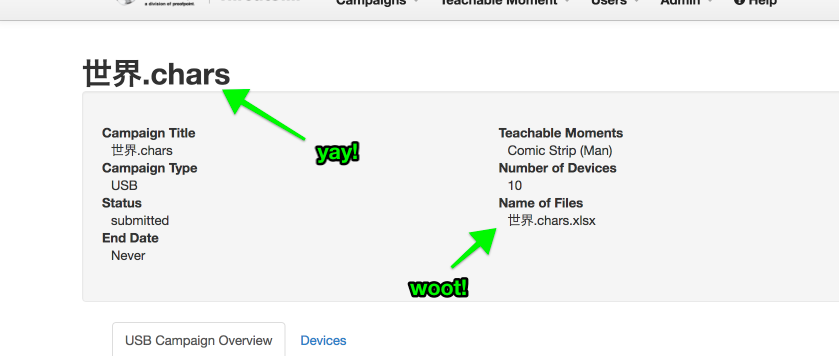
Now to test on a oneshot!
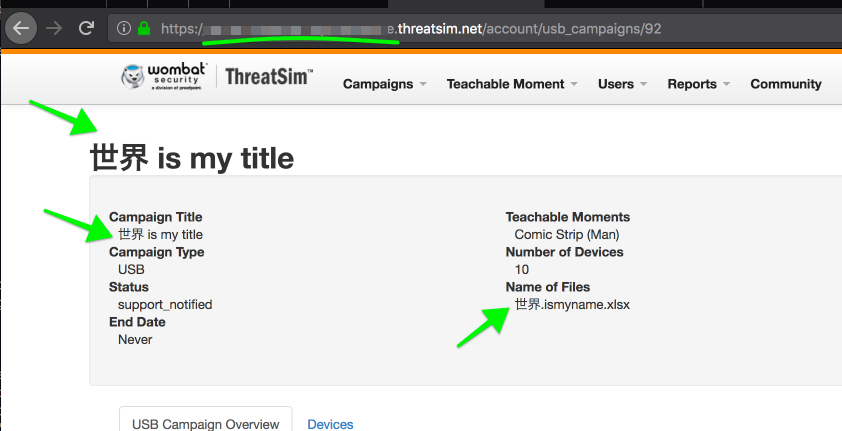
I’ve SSH’ed in to https://temporary_staging_environment_url_placeholder.com, and ran
ALTER TABLE threatsim_staging.usb_campaigns CONVERT TO CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
ALTER TABLE threatsim_staging.usb_campaign_file_details CONVERT TO CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
And it’s fixed!
Rails migration for character_set_name #
I’ve reset the usb_campaign_file_details table to latin1, latin1_swedish_ci, and I’m going to work on a rails migration that will update it.
Scratch that - a coworker suggested asking Jordan directly.
Asking Jordan for help #
note to reader: Jordan is on our DevOps team, and I linked to the gist I created in a JIRA ticket for Jordan/DevOps, to make these changes on production. I wanted them to have the context around my request, so I linked around a bit inside this doc.
Hi Jordan! There are two tables to change the character_set_name on.
I don’t know if it makes more sense to change the whole table, or just the column.
The tables are:
threatsim_staging.usb_campaign_file_detailsthreatsim_staging.usb_campaigns
These two commands, run on a oneshot, fixed all the above problems:
ALTER TABLE threatsim_staging.usb_campaigns CONVERT TO CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
ALTER TABLE threatsim_staging.usb_campaign_file_details CONVERT TO CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
Since I know almost nothing about updating production databases, and you know lots of things, I would love to know your professional opinion on how to implement the above changes.
For a quick-and-dirty check of what the problem is, read through Does our database support chinese characters?
Inspiration: